Trie
이론
트라이는 문자열을 저장하고 빠르게 조회하기 위한 트리 형태의 자료구조이다. 문자열 저장을 위해 메모리를 사용하지만 문자열 길이가 N일 때 시간 복잡도 $O(N)$의 탐색속도로 문자열을 조회할 수 있다. 자료구조를 구성하기 위해서 트라이는 각 문자열의 각각의 문자를 트리 형태로 다음과 같이 저장한다.
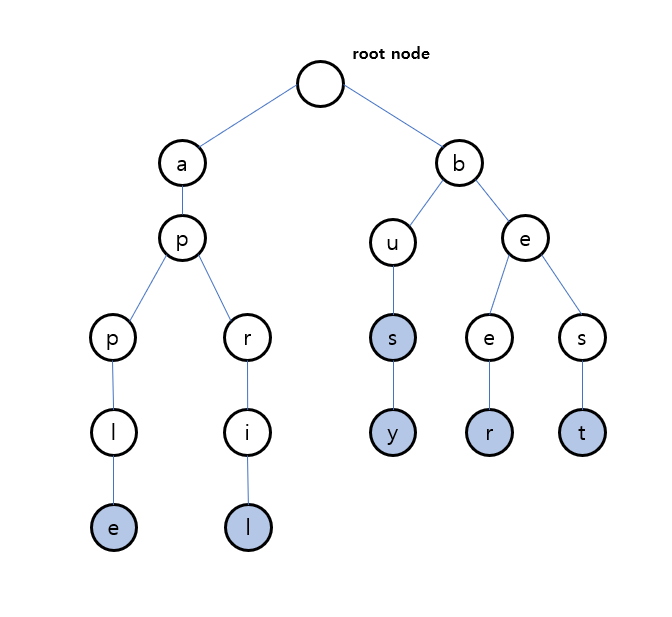
위 그림을 참고하여 트라이의 특징을 살펴보면 다음과 같다.
- 루트 노드는 항상 비어있고, 루트 노드의 하위 노드는 각 단어의 첫 글자들이다.
- 단어의 끝에 해당하는 리프 노드는
isEnd같은 변수로 표시를 해야 한다.
구현
이제 트라이를 한 번 구현해보도록 하자. Trie라는 클래스로 시작한다.
public class Trie {}
노드 설계
트라이의 특징에 따라서 노드 클래스를 구성해보면 다음과 같다.
public class Trie {
private Node root;
public Trie() {
this.root = new Node();
}
static class Node {
Map<Character, Node> child;
boolean isEnd;
public Node() {
//노드의 하위 노드들을 저장
this.child = new HashMap<>();
//이 노드가 단어의 끝인지 저장
this.isEnd = false;
}
}
}
이때 하위 노드를 Map으로 관리하여 현재 문자에 해당하는 하위 노드를 모두 조회할 수 있다. 그리고 트라이 자료구조에서는 빈 루트 노드를 하나 가지고 있어야 하므로 root라는 변수로 루트 노드를 관리하도록 하자.
문자열 삽입
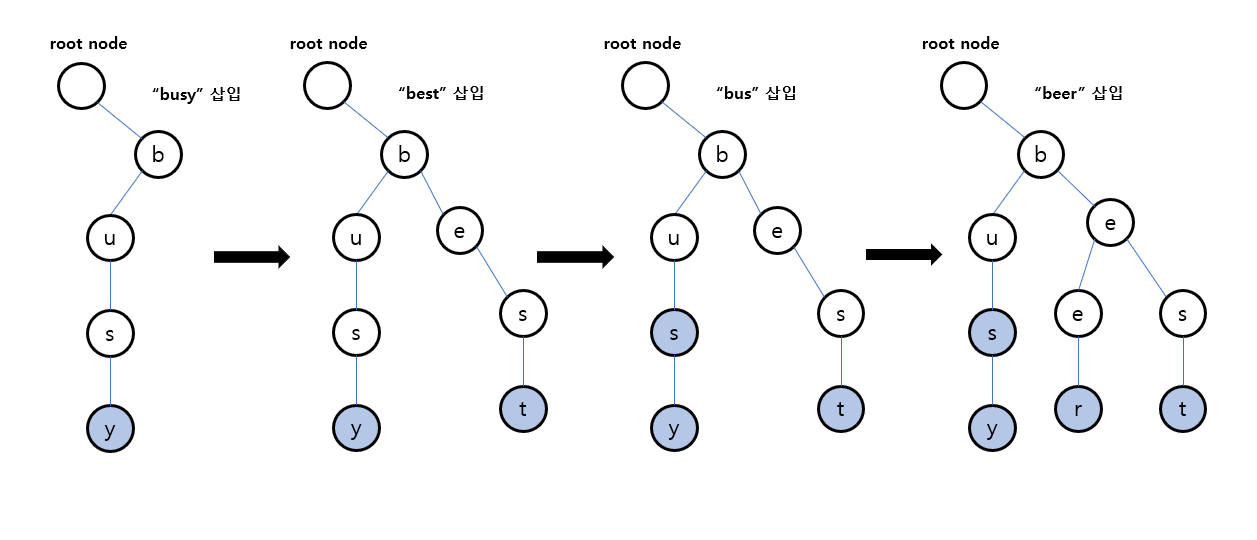
문자열 삽입 과정은 루트 노드부터 하위 노드를 담은 Map에서 삽입할 문자열의 한 문자씩 찾아본 뒤, 없다면 추가하고 만약에 존재하면 해당 하위 노드로 접근한다. 이는 Map.putIfAbsent()로 항상 하위 노드를 보장할 수 있다.
public void insert(String str) {
// 루트 노드부터 시작
Node node = this.root;
int len = str.length();
for (int i = 0; i < len; i++) {
char c = str.charAt(i);
// 문자에 해당하는 하위 노드가 없으면 put
node.child.putIfAbsent(c, new Node());
// 하위 노드로 이동 (putIfAbsent()로 항상 하위 노드임이 보장)
node = node.child.get(c);
}
// 반복이 끝나면 마지막 글자라는 의미이므로 끝을 명시
node.isEnd = true;
}
문자열 조회
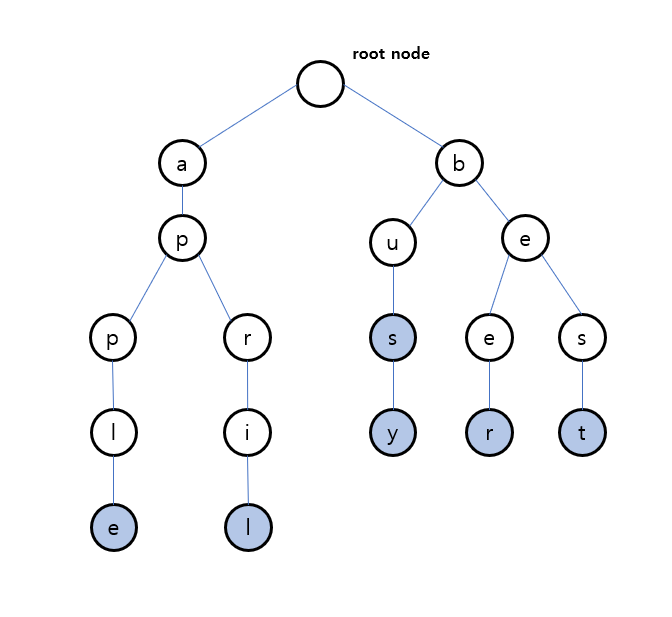
하위 노드들 중에서 조회하려는 문자가 있는지 확인하고, 중간에 하나라도 존재하지 않으면 탐색 실패이고, 마지막 문자를 찾으면 isEnd가 true인지 확인한다.
public boolean search(String str) {
Node node = this.root;
int len = str.length();
for (int i = 0; i < len; i++) {
node = node.child.get(str.charAt(i));
if (node == null) {
return false;
}
}
return node.isEnd;
}
문자열 자동 완성
트리에서 접두사로 시작하는 모든 문자열을 검색하도록 하자. 이를 위해 트리를 순회하는 재귀 호출을 구상해야 한다. 우선 전달된 접두사만큼 트라이에서 하위 노드를 탐색해나간다. 이때 탐색 도중 하위 노드가 존재하지 않으면 전달된 접두사가 포함된 문자열이 없다는 의미이므로 바로 List를 반환한다.
이후에는 깊이 우선 탐색 재귀 호출을 통해 모든 하위 노드를 탐색해나가며 현재 노드의 isEnd가 true면 리스트에 추가하면 된다.
public List<String> autoComplete(String prefix) {
List<String> results = new ArrayList<>();
Node node = this.root;
char[] prefixCharArray = prefix.toCharArray();
for (char ch : prefixCharArray) {
node = node.child.get(ch);
if (node == null) {
return results;
}
}
find(node, new StringBuilder(prefix), results);
return results;
}
private void find(Node node, StringBuilder sb, List<String> results) {
if (node.isEnd) {
results.add(sb.toString());
}
for (Map.Entry<Character, Node> entry : node.child.entrySet()) {
sb.append(entry.getKey());
find(entry.getValue(), sb, results);
sb.deleteCharAt(sb.length() - 1);
}
}
문자열 삭제
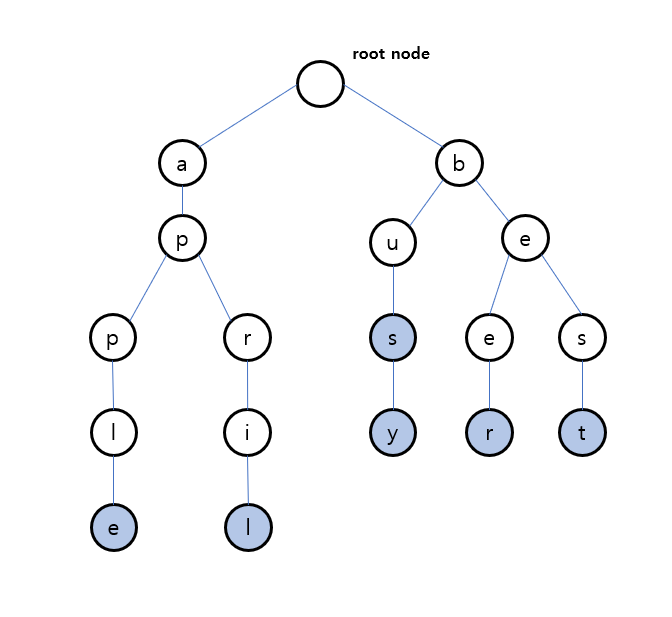
삭제는 외부로부터 문자열 삭제를 요청하면, 내부적으로 재귀 호출을 통해 트리에 저장된 노드에 대해서 isEnd를 false로 설정하면 약한 삭제가 된다. 이때 만약에 현재 노드가 하위 노드를 가지고 있지 않으면 현재 노드를 메모리 효율성을 위해 삭제시킨다.
public boolean delete(String str) {
boolean result = delete(this.root, str, 0);
return result;
}
private boolean delete(Node node, String str, int idx) {
char ch = str.charAt(idx++);
Node cur = node.child.get(ch);
// 현재 노드에서 문자에 해당하는 하위 노드가 없으면 false 리턴
if (cur == null) {
return false;
}
// 인덱스가 문자열 끝에 도달했을 때
if (idx == str.length()) {
if (!cur.isEnd) {
return false;
}
// isEnd를 false로 바꿔 약한 삭제 처리
cur.isEnd = false;
// 만약 현재 노드가 아무런 하위 노드를 가지고 있지 않으면 현재 노드를 삭제 처리
if (cur.child.isEmpty()) {
node.child.remove(ch);
}
// 인덱스가 문자열의 끝에 도달하지 않았을 때
} else {
// 현재 노드를 기준으로 재귀 호출 후 삭제를 실패하면 false 반환
if (!delete(cur, str, idx)) {
return false;
}
// 삭제 성공 이후에 현재 노드가 다른 문자열을 저장하고 있는 것이 아니고,
// 현재 노드의 하위 노드가 모두 비어있으면 현재 노드를 삭제
if (!cur.isEnd && cur.child.isEmpty()) {
node.child.remove(ch);
}
}
return true;
}
이때 현재 node의 하위 노드를 child가 아닌 cur라고 명명하는 이유는 루트 노드가 하위 노드만 가지고 있는 노드이기 때문이라고 생각하면 된다.
전체 코드
전체 코드는 다음과 같다.
import java.util.*;
public class Trie {
private Node root;
public Trie() {
this.root = new Node();
}
public void insert(String str) {
// 루트 노드부터 시작
Node node = this.root;
int len = str.length();
for (int i = 0; i < len; i++) {
char c = str.charAt(i);
// 문자에 해당하는 하위 노드가 없으면 put
node.child.putIfAbsent(c, new Node());
// 하위 노드로 이동 (putIfAbsent()로 항상 하위 노드임이 보장)
node = node.child.get(c);
}
// 반복이 끝나면 마지막 글자라는 의미이므로 끝을 명시
node.isEnd = true;
}
public boolean search(String str) {
Node node = this.root;
int len = str.length();
for (int i = 0; i < len; i++) {
node = node.child.get(str.charAt(i));
if (node == null) {
return false;
}
}
return node.isEnd;
}
public List<String> autoComplete(String prefix) {
List<String> results = new ArrayList<>();
Node node = this.root;
char[] prefixCharArray = prefix.toCharArray();
for (char ch : prefixCharArray) {
node = node.child.get(ch);
if (node == null) {
return results;
}
}
find(node, new StringBuilder(prefix), results);
return results;
}
private void find(Node node, StringBuilder sb, List<String> results) {
if (node.isEnd) {
results.add(sb.toString());
}
for (Map.Entry<Character, Node> entry : node.child.entrySet()) {
sb.append(entry.getKey());
find(entry.getValue(), sb, results);
sb.deleteCharAt(sb.length() - 1);
}
}
public boolean delete(String str) {
boolean result = delete(this.root, str, 0);
return result;
}
private boolean delete(Node node, String str, int idx) {
char ch = str.charAt(idx++);
Node cur = node.child.get(ch);
if (cur == null) {
return false;
}
if (idx == str.length()) {
if (!cur.isEnd) {
return false;
}
cur.isEnd = false;
if (cur.child.isEmpty()) {
node.child.remove(ch);
}
} else {
if (!delete(cur, str, idx)) {
return false;
}
if (!cur.isEnd && cur.child.isEmpty()) {
node.child.remove(ch);
}
}
return true;
}
static class Node {
Map<Character, Node> child;
boolean isEnd;
public Node() {
//노드의 하위 노드들을 저장
this.child = new HashMap<>();
//이 노드가 단어의 끝인지 저장
this.isEnd = false;
}
}
}
댓글남기기