자바 리액티브 프로그래밍
자바는 8 버전 이후 빠르게 진화하기 시작했다. Stream API를 통한 선언적 데이터 처리와 람다 표현식을 이용한 동작 파라미터화는 자바를 절차적 언어에서 함수형 스타일로 확장시켰다. 이어 자바 21에서는 가상 스레드(Virtual Thread) 를 통해 I/O Bound 작업을 훨씬 효율적으로 처리할 수 있게 되었다.
이러한 변화 중에서도 자바 9에서 추가된 Flow API는 특히 주목할 만하다. 자바가 리액티브 스트림을 표준 API로 정식 지원하기 시작했다는 의미이며, 자바 기반의 리액티브 프로그래밍을 구현할 수 있다는 신호이기도 하다.
리액티브 프로그래밍
리액티브 프로그래밍은 리액티브 스트림 사양을 기반으로 한 비동기 프로그래밍 방식이다. 하지만 이 한 문장만으로는 리액티브 프로그래밍이 어떤 철학을 담고 있는지 쉽게 와닿지 않는다. 그래서 그 배경이 된 리액티브 매니페스토를 먼저 살펴보자. 이는 리액티브 시스템과 프로그래밍의 핵심 원칙을 공식적으로 정리한 선언문이다.
리액티브 매니페스토
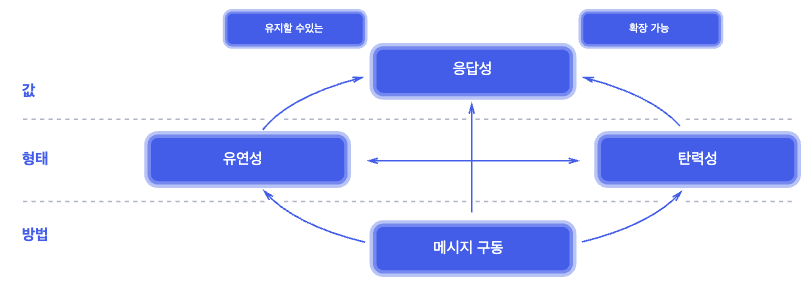
- 반응성 (Responsive): 시스템이 가능한 한 제 시간에 응답을 제공할 수 있어야 한다. 이는 단순한 사용자 만족을 넘어 오류 탐지 및 대응 가능성을 높이는 기반이다.
- 탄력성 (Resilient): 장애 발생에도 응답성을 유지해야 한다. 이를 위해 복제, 격리, 비동기 위임 등의 설계가 필요하다.
- 유연성 (Elastic): 부하가 증가하더라도 시스템이 자원을 탄력적으로 할당하여 반응성을 유지해야 한다.
- 메시지 기반 (Message-Driven): 구성 요소 간 통신은 비동기 메시지 전달을 통해 이루어져야 하며, 이는 느슨한 결합과 위치 투명성을 보장한다.
이 네 가지 원칙을 코드 수준에서 실천하는 프로그래밍 방식이 바로 리액티브 프로그래밍이다.
리액티브 프로그래밍과 필요성
전통적인 애플리케이션은 하나의 요청에 스레드를 할당해 응답까지 담당하여 처리하는 구조이다. 이때 데이터베이스, 네트워크, 파일 시스템 접근 등의 I/O 작업은 Blocking I/O 방식으로 동작한다.
이 구조는 단순하고 직관적이지만, 문제는 I/O 작업이 오래 걸릴 경우 스레드가 그 시간만큼 대기해야 한다. 멀티코어 CPU와 대규모 트래픽 상황에서 이러한 대기 시간이 시스템의 병목으로 이어진다. 요청마다 스레드를 하나씩 할당하는 구조는 동시 요청이 늘수록 지연과 장애 가능성을 높인다.
이 문제를 해결하기 위해 등장한 개념이 바로 비동기와 Non-blocking 처리이다. 리액티브 프로그래밍은 이 원칙을 기반으로, 데이터를 한 번에 처리하지 않고 시간에 따라 흘러오는 데이터 스트림을 비동기적으로 처리한다. 즉, I/O 작업의 지연이 발생해도 CPU는 다른 작업을 수행할 수 있다. 그리고 결과가 준비되면 이벤트를 통해 반응하고 후속 처리를 수행한다.
동기 / 비동기와 Blocking / Non-Blocking의 차이점
공부 중에 비동기와 Non-Blocking의 개념이 비슷한 것 같아서 좀 더 찾아봤다.
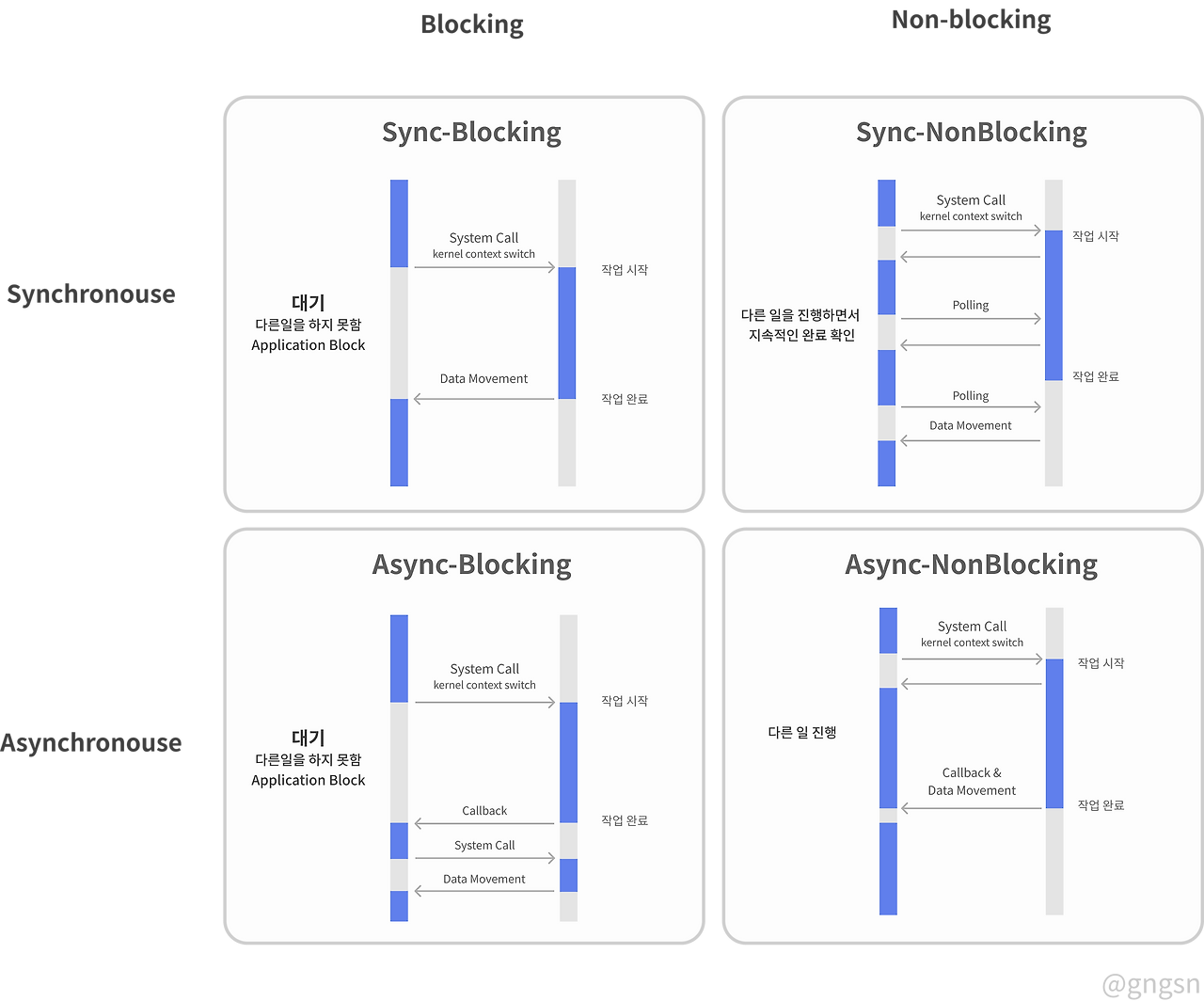
| 작업 유형 | 설명 |
|---|---|
| 동기 - Blocking | 요청을 보낸 스레드가 결과를 받을 때까지 대기한다. 일반적인 스프링 MVC가 활용하는 방식이다. |
| 동기 - Non-Blocking | 요청을 보낸 스레드가 바로 반환되지만, 결과를 직접 폴링해야 한다. |
| 비동기 - Blocking | 작업은 비동기로 실행되지만 요청을 보낸 스레드가 대기한다. |
| 비동기 - Non-Blocking | 작업이 비동기로 실행되고 결과는 콜백 / 이벤트로 처리된다. |
- 결과를 직접 받으면 동기, 콜백/이벤트로 받으면 비동기
- 호출한 스레드가 기다리면 Blocking, 기다리지 않으면 Non-Blocking
나는 이렇게 이해했다.
리액티브 프로그래밍의 특징
리액티브 프로그래밍의 특징은 다음과 같다.
발행 - 구독
리액티브 프로그래밍은 기본적으로 데이터 발행자와 이를 구독하여 처리하는 구독자의 상호작용을 중심으로 동작한다.
데이터 스트림
데이터가 일정 시간 간격으로 순차적으로 방출되는 데이터의 흐름을 의미한다. 사용자 입력, 애플리케이션 프로퍼티 값, 캐시, 데이터베이스 조회 결과 등 여러 소스로부터 생성될 수 있다.
구독자는 새로운 데이터가 방출될 때마다 이를 비동기적으로 수신하고, 필요에 따라 가공하거나 변환하여 또 다른 스트림을 발행할 수 있다. 즉, 리액티브 프로그래밍에서는 시간에 따라 연속적으로 변화하는 데이터를 반응형으로 다룬다.
그리고 데이터 스트림은 생성 시점과 소비 방식에 따라서 두 개의 시퀀스로 구분된다.
| 구분 | 설명 | 예시 |
|---|---|---|
| Cold Sequence (Cold Publisher) | 구독자가 구독할 때마다 새로운 데이터 흐름이 생성된다. 구독자는 항상 스트림의 처음부터 데이터를 수신하며, 다른 구독자와 데이터가 공유되지 않는다. | 채팅 기록 불러오기, 동영상 다시보기 |
| Hot Sequence (Hot Publisher) | 이미 생성된 데이터 스트림을 여러 구독자가 공유한다. 구독자는 현재 시점 이후의 데이터만 수신하며, 과거 데이터는 받지 않는다. | 실시간 채팅방, 라이브 방송 |
업스트림과 다운스트림
리액티브 프로그래밍에서 업스트림과 다운스트림은 두 관점에 따라서 다르게 정의된다. 데이터 파이프라인에서는 ‘데이터의 흐름’을 기준으로, 리액티브 스트림에서는 ‘신호(프로토콜)의 방향’을 기준으로 구분한다. 이를 정리하면 다음과 같다.
| 구분 | 파이프라인 구조 관점 | 신호(프로토콜) 방향 관점 |
|---|---|---|
| 업스트림 (Upstream) | 데이터의 생성·공급 위치 | 요청 및 제어 신호가 상류 방향으로 전달됨 (request, cancel) |
| 다운스트림 (Downstream) | 데이터의 소비·처리 위치 | 데이터·완료·에러 신호가 하류 방향으로 전달됨 (onNext, onComplete, onError) |
비동기
리액티브 프로그래밍에서는 요청에 대한 응답이 올 때 까지 스레드가 기다리지 않고 응답이 준비되었을 때 스레드나 이벤트 루프가 받아서 처리한다.
이벤트 루프란?
비동기 작업의 완료 이벤트를 감지하고, 등록된 콜백 함수를 실행하는 루프 구조이다. 즉, I/O 요청의 결과를 기다리지 않고 응답이 준비되면 이벤트 루프가 해당 콜백을 스케줄링에서 실행한다. 자바에서는 언어 차원이 아니라 Netty, Project Reactor, Vert.x 같은 프레임워크에서 구현되어 있다.
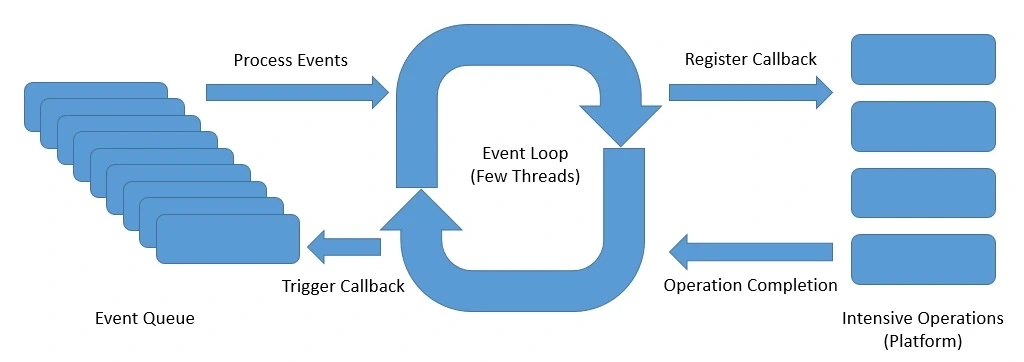
비동기 이벤트 스트림
현실 세계에서의 사례를 본다면 마우스 클릭 이벤트가 있다. 사용자는 버튼을 클릭해서 이벤트를 생성할 수 있고, 프로그램은 이를 구독하여 반응한다. 이 관계를 설명하는 디자인 패턴이 바로 옵저버 패턴이며, 리액티브 스트림은 이를 더 확장하여 비동기 데이터 처리로 발전시킨 형태다.
역압력 (Backpressure)
리액티브 프로그래밍에서 매우 중요한 개념으로, 먼저 프로듀서와 컨슈머 사이의 푸시와 풀 개념을 짚고 넘어가도록 하자. 컨슈머는 프로듀서가 만들어내는 이벤트를 구독하고 프로듀서는 컨슈머에게 이벤트를 푸시한다.
하지만 이때 프로듀서의 생산율을 컨슈머의 소비율이 따라가지 못하면 이벤트를 버퍼에 임시로 담아둬야 한다. 버퍼의 한도를 초과하는 이벤트는 유실될 수 있다. 이 경우 프로듀서는 버려진 이벤트를 재전송 해야 한다.
이런 문제를 해결하기 위해 리액티브 스트림에서는 푸시 대신 풀 방식을 도입했다. 컨슈머가 자신의 처리 속도에 맞게 데이터를 요청함으로, 안정적인 데이터 흐름을 유지할 수 있다.
Flow API 알아보기
Flow API는 자바 9 부터 java.util.concurrent.Flow에 추가된 클래스로, 정적 컴포넌트 하나를 포함하며 인스턴스화 할 수 없다. 해당 클래스는 4개의 중첩 인터페이스를 포함한다. 하나씩 알아보도록 하자.
Flow 중첩 인터페이스 종류
Publisher
@FunctionalInterface
public interface Publisher<T> {
void subscribe(Subscriber<? super T> s);
}
잠재적으로 무한한 수의 요소를 만들어낼 수 있고, 구독자가 요청하는 만큼만 발행한다. subscribe() 메서드를 통해 구독자가 발행자를 구독할 수 있다.
Subscriber
public interface Subscriber<T> {
void onSubscribe(Subscription s);
void onNext(T t);
void onError(Throwable t);
void onComplete();
}
언제 얼마만큼의 요소를 처리할 수 있을 지 결정하고 구독한다. 구독자는 onSubscribe() 메서드의 파라미터로 구독을 전달받아서 구독에 데이터를 요청하고, 반환 받은 데이터를 onNext() 메서드를 사용해서 처리한다. 그리고 에러 발생 시 onError() 메서드로 에러를 처리하고, onComplete()로 처리를 완료한다.
Subscription
public interface Subscription {
public void request(long n);
public void cancel();
}
구독자가 발행자를 구독할 때 발행자는 내부적으로 onSubscribe()를 호출해 Subscription 객체를 전달한다. 이를 통해 구독자와 발행자의 관계를 나타낸다. request()로 발행자에게 주어진 개수의 이벤트를 처리할 수 있음을 알린다. cancel()로 발행자에게 더 이상 이벤트를 받지 않는다는 것을 통지한다.
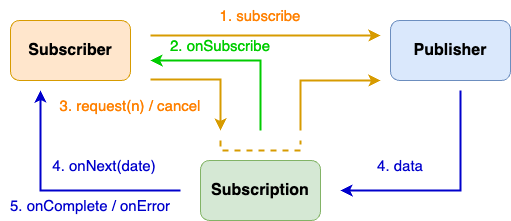
위 3개의 객체의 관계를 그림으로 나타내면 다음과 같다. 그리고 자바 9 Flow 명세서에서는 이들 인터페이스의 구현에 대해서 다음과 같은 규칙을 요구한다.
- Publisher → Subscriber (데이터 전송 규칙)
Publisher는 반드시request(n)으로 요청된 개수 이하의 데이터만onNext()로 전달해야 한다.- 요청한 개수보다 적게 보내는 것은 허용된다.
- 모든 데이터 전송이 끝나면
onComplete()호출, 오류 발생 시onError()호출로 종료한다.
- Subscriber → Publisher (Backpressure)
Subscriber는 처리 가능한 만큼만 데이터를 요청(request(n))해야 한다.- 이를 통해 Publisher에 역압력을 행사하며, 과도한 데이터 유입을 방지한다.
onComplete()나onError()실행 중에는 Publisher 또는 Subscription의 메서드를 호출하면 안 된다.
- Subscription의 일관성
Publisher와Subscriber는 하나의 Subscription을 공유하며, 서로의 역할을 명확히 구분해야 한다.Subscriber는onSubscribe()나onNext()안에서request()를 동기적으로 호출 가능하다.cancel()은 여러 번 호출해도 한 번만 유효해야 하며, 스레드에 안전해야 한다.- 같은
Subscriber가 재구독하는 것은 권장되지 않지만, 명세상 예외를 강제하지 않는다.
Processor
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {}
처리 단계를 나타내며 발행자 인터페이스와 구독자 인터페이스를 상속받는다. 이는 리액티브 스트림에서 처리하는 이벤트의 변환 단계를 나타낸다. 즉 데이터를 변환하는 책임을 담당하는 클래스다.
처리 중 Processor가 에러를 수신하면 이로부터 회복하고 Subscription은 취소로 간주하며, onError()로 모든 Subscriber에 에러를 전파할 수 있다.
마지막 Subscriber가 Subscription을 취소하면 Processor는 자신의 상위(업스트림) Subscription도 취소하여 신호를 전파해야 한다.
Flow API 활용해보기
이제 각 도시의 온도를 보여주는 온도계 프로그램을 리액티브 프로그래밍으로 구현해보도록 하자. 온도와 관련된 도메인 객체는 다음과 같다.
import java.util.Random;
public class TempInfo {
public static final Random random = new Random();
private final String town;
private final int temp;
public TempInfo(String town, int temp) {
this.town = town;
this.temp = temp;
}
public static TempInfo fetch(String town) {
// 10 분의 1 확률로 온도 가져오기 작업 실패
if (random.nextInt(10) == 0) {
throw new RuntimeException("에러 발생!!!!");
}
return new TempInfo(town, random.nextInt(100));
}
// getter toString
}
Subscriber
Subscriber가 요청할때마다 해당 도시의 온도를 전송하도록 Subscription을 구현한다.
public class TempSubscription implements Subscription {
private final Subscriber<? super TempInfo> subscriber;
private final String town;
public TempSubscription(
Subscriber<? super TempInfo> subscriber,
String town
) {
this.subscriber = subscriber;
this.town = town;
}
@Override
public void request(long n) {
// Subscriber가 만든 요청을 한 개씩 반복
for (long i = 0L; i < n; i++) {
try {
// 현재 온도를 Subscriber로 전달
subscriber.onNext(TempInfo.fetch(town));
} catch (Exception e) {
// 온도 가져오기를 실패하면 Subscriber로 에러를 전달
subscriber.onError(e);
break;
}
}
}
@Override
public void cancel() {
// 구독이 취소되면 완료 신호를 Subscriber로 전달
subscriber.onComplete();
}
}
Subscription
새 데이터를 얻을 때마다 Subscription이 전달한 온도를 출력하고 새로운 온도 정보를 요청하는 Subscriber를 다음과 같이 구현한다.
public class TempSubscriber implements Subscriber<TempInfo> {
private Subscription subscription;
@Override
public void onSubscribe(Subscription subscription) {
this.subscription = subscription;
subscription.request(1);
}
@Override
public void onNext(TempInfo temp) {
System.out.println(temp);
subscription.request(1);
}
@Override
public void onError(Throwable t) {
System.out.println(t.getMessage());
}
@Override
public void onComplete() {
System.out.println("종료");
}
}
백프레셔를 활용해서 구독을 시작할때부터 종료 전까지 1건의 데이터를 소비하도록 구현했다.
Publisher 정의 및 실행
이제 이 구조가 동작하도록 Publisher를 만들고 구독을 해봤다.
public class Main {
public static void main(String[] args) {
getTemperatures("서울").subscribe(new TempSubscriber());
}
private static Publisher<TempInfo> getTemperatures(String town) {
return subscriber -> subscriber.onSubscribe(
new TempSubscription(subscriber, town)
);
}
}
문제점
TempInfo의 작업 실패 코드를 삭제하면 어떤 일이 발생할까?
// 10 분의 1 확률로 온도 가져오기 작업 실패
if (random.nextInt(10) == 0) {
throw new RuntimeException("에러 발생!!!!");
}
해당 코드를 삭제한 상태에서 실행을 하면 StackOverflowError가 발생한다. 왜 그럴까? onNext()로 받을 때마다 TempSubscription으로 요청을 보내면 다시 또 재귀 호출을 하는 문제가 있다. 그렇게 호출 스택이 쌓이다가 결국 StackOverflowError가 발생한다. 해당 문제를 해결하기 위해서 Executor를 활용해서 다른 스레드에서 TempSubscriber로 전달하는 방법이 있다.
public class TempSubscription implements Subscription {
private static final ExecutorService executor = Executors.newSingleThreadExecutor();
// ...
@Override
public void request(long n) {
executor.submit(() -> {
// Subscriber가 만든 요청을 한 개씩 반복
for (long i = 0L; i < n; i++) {
try {
// 현재 온도를 Subscriber로 전달
subscriber.onNext(TempInfo.fetch(town));
} catch (Exception e) {
// 온도 가져오기를 실패하면 Subscriber로 에러를 전달
subscriber.onError(e);
break;
}
}
});
}
@Override
public void cancel() {
// 구독이 취소되면 완료 신호를 Subscriber로 전달
subscriber.onComplete();
}
}
데이터 변환하기
Processor는 Subscriber이며 동시에 Publisher이다. 이를 활용해서 Publisher를 구독한 다음 수신한 데이터를 가공해서 Subscriber를 다시 제공하도록 하자. 앞서 생성된 온도가 화씨라고 가정하고 이를 섭씨로 변환해서 Subscriber에 전달하도록 하자.
public class TempProcessor implements Processor<TempInfo, TempInfo> {
private Subscriber<? super TempInfo> subscriber;
@Override
public void subscribe(Subscriber<? super TempInfo> subscriber) {
this.subscriber = subscriber;
}
@Override
public void onSubscribe(Subscription subscription) {
subscriber.onSubscribe(subscription);
}
@Override
public void onNext(TempInfo temp) {
subscriber.onNext(
new TempInfo(
temp.getTown(),
convertToCelsius(temp.getTemp())
)
);
}
@Override
public void onError(Throwable throwable) {
subscriber.onError(throwable);
}
@Override
public void onComplete() {
subscriber.onComplete();
}
private int convertToCelsius(int temp) {
return (temp - 32) * 5 / 9;
}
}
그 다음 다음과 같이 Processor를 등록한다.
public class Main {
public static void main(String[] args) {
getCelsiusTemperatures("서울").subscribe(new TempSubscriber());
}
private static Publisher<TempInfo> getCelsiusTemperatures(String town) {
return subscriber -> {
TempProcessor tempProcessor = new TempProcessor();
tempProcessor.subscribe(subscriber);
tempProcessor.onSubscribe(new TempSubscription(subscriber, town));
};
}
}
여기서 개인적으로 헷갈렸던 것이 바로 Publisher와 Processor가 데이터의 발행자 역할을 하거나 할 수 있는데, subscribe()로 Subscriber를 구독한다는 것이었다. 이 부분을 발행자가 구독자를 자신의 구독자로서 “등록”한다는 개념으로 보니까 좀 더 이해가 잘 됐던 것 같다.
왜 register()같은 메서드 네이밍도 있는데 굳이 이렇게 했나 궁금해서 AI에게 물어보니까 이는 리액티브 스트림이 옵저버 패턴의 확장으로 설계되었기 때문이라고 했다. 전통적인 옵저버 패턴에서는 다음과 같은 코드로 옵저버를 등록했다.
observable.subscribe(observer);
observable이 변경 가능한 자원이기 때문에 발행자라고 본다면, 해당 호출은 소비자인 옵저버가 발행자를 구독하는 의미인데도 호출 흐름은 반대로 이루어져 있다. 이러한 관례를 유지하다보니 Flow API에서도 이러한 모호함이 남아있다고 한다.
따라서 Publisher나 Processor가 subscribe()를 호출하면 Subscriber를 등록하는 행위이며, 의미상으로는 해당 메서드로 전달된 Subscriber가 호출한 객체(Publisher나 Processor)를 구독한다고 이해하면 된다.
오랜만에 이렇게 길게 작성할 정도로 리액티브 프로그래밍은 상당히 이해하기 난해했다. 확실히 이렇게 아예 모르는 것을 접할 때에는 책이나 강의가 단계적으로 차근차근 설명해줘서 좋다고 생각한다.
댓글남기기