프로젝트 리액터
Spring Webflux로 넘어가기 전에 프로젝트 리액터부터 알아보고 가도록 하자. 프로젝트 리액터는 JVM 기반의 리액티브 프로그래밍 라이브러리로, 리액티브 스트림 사양을 구현한 대표적인 기술이다. Spring WebFlux는 이 Reactor를 기반으로 구축되었으며, Java 9의 Flow API와도 호환성을 지원한다.
Flux와 Mono
리액터의 핵심 컴포넌트인 reactor core 모듈은 자바 8을 사용하며 리액티브 스트림 명세를 구현한다. 리액터는 스트림의 Publisher 인터페이스 구현체인 Flux와 Mono라는 조합성 있는 리액티브 타입을 제공한다.
Flux는 0에서 N개까지의 아이템으로 구성된 비동기 시퀀스를 나타내며, 에러나 완료 신호를 통해 종결된다. Mono는 onNext 시그널을 통해 최대 1개의 아이템을 방출하거나 onError 시그널을 통해 1개의 에러를 방출하고, onComplete 시그널을 통해 스트림을 종결하는 특수한 발행자다.
Flux와 Mono는 불변 시퀀스이며, 각 연산자는 기존 시퀀스를 변환해 새로운 Publisher를 생성한다. 즉, 모든 연산은 체이닝을 통해 새로운 Flux 또는 Mono 파이프라인을 만들어낸다.
주요 데이터 처리 연산자
리액티브 스트림에서는 데이터 스트림 위에 여러 연산자를 조합해 데이터 변환, 필터링, 집계, 비동기 결합 등을 수행할 수 있다. Flux/Mono의 진가는 바로 리스트 조작(map, flatMap, filter, reduce 등)과 비동기 조합(zip, concat, merge 등)에 있으며, 이를 표로 정리하면 다음과 같다.
| 연산자 이름 | 시그니처 예시 | 설명 |
|---|---|---|
| map | map(Function<? super T, ? extends R>) |
각 요소에 함수를 적용해 새로운 값으로 매핑한다. |
| flatMap | flatMap(Function<? super T, ? extends Publisher<? extends R>>) |
각 요소를 비동기 작업으로 매핑하고, 이들의 비동기 결과를 하나의 Flux로 병합한다. 내부 작업은 병렬로 실행될 수 있으며, 순서 보장은 하지 않는다. |
| filter | filter(Predicate<? super T>) |
입력값을 평가해 조건을 만족하는 요소만 통과시킨다. |
| reduce | reduce(BiFunction<? super T, ? super T, ? extends T>) |
순차적으로 두 개씩 값을 결합해 단일 결과를 만든다. |
| zip | zip(Flux<? extends T>, Flux<? extends U>) |
두 개 이상의 Flux를 인덱스별로 짝지어 튜플이나 특정 타입으로 방출한다. |
| concatWith | concatWith(Publisher<? extends T>) |
첫 번째 스트림이 완료된 뒤 두 번째 스트림을 순차적으로 이어 붙여 방출한다. |
| mergeWith | mergeWith(Publisher<? extends T>) |
두 스트림을 병렬로 섞어서 방출한다(순서 보장되지 않음). |
| retry | retry(long numRetries) |
에러 발생 시 지정한 횟수만큼 재시도하여 스트림을 재구독한다. |
| onErrorResume | onErrorResume(Function<Throwable, ? extends Publisher<? extends T>>) |
에러가 발생하면 다른 Publisher로 대체하여 스트림을 종료하지 않고 계속 흐름을 이어간다. |
| subscribeOn | subscribeOn(Scheduler scheduler) |
구독 시점부터 전체 파이프라인의 실행을 지정된 스케줄러 위에서 수행하도록 한다. |
| publishOn | publishOn(Scheduler scheduler) |
지정된 위치부터 이후 연산자들을 다른 스케줄러에서 실행하도록 전환한다. |
코드를 통한 실습
코드로 Flux나 Mono를 생성해 각각의 데이터 처리 연산자에 대한 실습을 수행하면서 그 외의 연산자들도 추가적으로 학습해보았다. 이를 위해서 우선 다음과 같이 프로젝트 리액터 관련 의존성을 추가하였다. 그리고 각 연산자마다 이해를 돕기 위해서 공식 Javadoc에서 시간의 흐름에 다른 데이터의 변환을 시각화한 마블 다이어그램을 첨부한다.
dependencies {
implementation 'io.projectreactor:reactor-core:3.8.0'
testImplementation 'io.projectreactor:reactor-test:3.8.0'
}
Flux 또는 Mono 생성
Flux나 Mono는 다음과 같이 코드로 만들 수 있다.
Flux.just(1, 2, 3, 4, 5);
// 연속된 값으로 이루어진 경우
Flux.range(1, 5);
Mono.just(1);
range()는 연속적인 Flux를 만들 때 사용하는 것으로, 두 번째 인자는 끝 값을 가리키는 것이 아닌 생성될 데이터의 개수를 나타낸다. 따라서 해당 값을 음수로 선언할 경우 IllegalArgumentException이 발생한다.
map
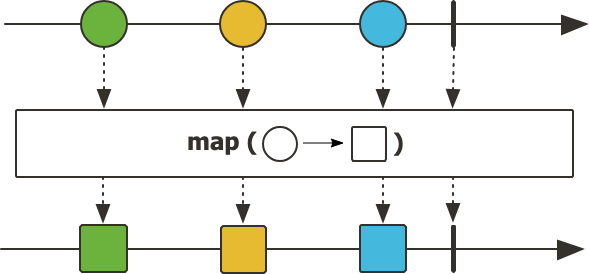
map()은 각 요소를 새로운 값으로 매핑한다는 의미이다. Flux를 다음과 같이 생성해보자.
Flux<Integer> flux = Flux.just(1, 2, 3, 4, 5)
.map(i -> i * 10)
.doOnNext(i -> System.out.println("result : " + i))
.filter(i -> i > 20);
doOnNext()는 데이터를 내보내기 직전에 호출되는 사이드 이펙트 연산자다. 일반적으로 로그 출력, 디버깅, 메트릭 수집 등 스트림의 흐름을 변경하지 않는 관찰 목적으로 사용된다. 이 외에도 doOn으로 시작하는 메서드들은 모두 리액티브 스트림의 라이프사이클을 관찰하기 위한 훅이므로, 비즈니스 로직 처리는 지양해야 한다.
소비자 작성
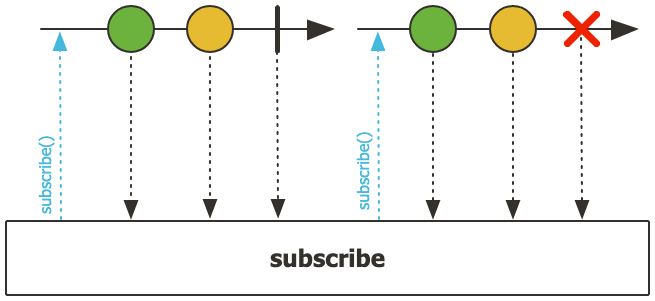
앞서 생성한 Flux를 구독해서 데이터를 처리해보도록 하자. Flux 또는 Mono에 대한 소비자는 subscribe()로 구현할 수 있으며, 다음과 같은 메서드들을 지원한다.
subscribe();
subscribe(Consumer<? super T> consumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer);
각 상황에 따라서 소비자와 작업 종료 시 콜백, 그리고 Subscription을 정의한다. 참고로 subscribe()가 호출되지 않으면 데이터의 생산은 이루어지지 않기 때문에 doOnNext()를 통한 출력도 이루어지지 않는다.
flux.subscribe(
data -> System.out.println("onNext: " + data),
err -> System.err.println("onError: " + err),
() -> System.out.println("onComplete")
);
출력 결과는 다음과 같다.
result : 10
result : 20
result : 30
onNext: 30
result : 40
onNext: 40
result : 50
onNext: 50
onComplete
여기서 각 데이터가 map()을 거친 다음에 doOnNext()로 출력된다. doOnNext()는 filter() 이전에 처리되기 때문에 모든 요소가 출력된다. 이후 filter()를 거쳐서 최종적으로 통과된 데이터가 소비자에 의해 소비되는 모습을 볼 수 있다.
테스트 코드 작성
Flux나 Mono에 대한 테스트 코드 작성법이 궁금해서 공식문서를 살펴봤는데, StepVerifier라는 객체로 대부분 해결되는 것 같아서 앞서 작성한 Flux에 대한 테스트 코드를 다음과 같이 작성해봤다.
StepVerifier.create(fluxUsingMap)
.expectNext(30, 40, 50)
.verifyComplete();
여기서 디버깅을 좀 더 수월하게 테스트와 테스트 단계별로 이름을 명칭할 수 있다.
StepVerifierOptions option = StepVerifierOptions
.create()
.scenarioName("Flux 필터링 테스트");
StepVerifier.create(fluxUsingMap, option)
.expectNext(20).as("20 이상의 값도 필터링 가능하다.")
.expectNext(30, 40, 50)
.verifyComplete();
// 결과: [Flux 필터링 테스트] expectation "20 이상의 값도 필터링 가능하다." failed
그 외에도 오류 상황에 대한 테스트나 생성될 데이터의 개수를 기대하는 테스트도 할 수 있다.
flatMap
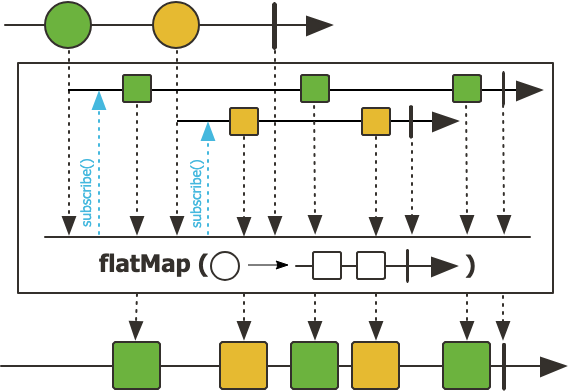
해당 연산자는 각 요소를 비동기 작업으로 매핑한다고 하였는데, 이 말이 어떤 말인지 직접 알아보자.
// flatMap을 통해 비동기적으로 여러 Mono의 결과를 병합하여 Flux<User>를 생성한다.
Flux.just("user1", "user2", "user3")
.flatMap(id -> Mono.just(id)
.delayElement(Duration.ofMillis((long) (Math.random() * 100)))
.doOnNext(v -> System.out.println("processing: " + v)))
.subscribe(v -> System.out.println("result: " + v));
Thread.sleep(500);
delayElement()는 onNext 신호(값 방출)를 지정된 시간만큼 지연시키는 Reactor의 비동기 지연 연산자이다.
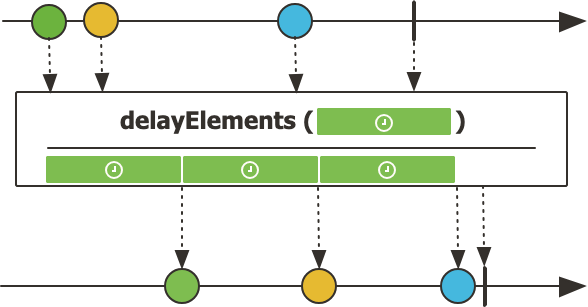
이 연산자를 사용하면 Mono 또는 Flux의 각 요소가 랜덤한 시간 뒤에 비동기적으로 방출되도록 만들 수 있다. 이 연산자를 사용한 이유는 flatMap()이 각 요소의 순서를 보장해주지 않는 것을 확인하기 위해서이다.
그리고 Thread.sleep()을 호출한 이유는 리액터의 내부 스케줄러의 워커 스레드는 대부분 데몬 스레드이기 때문이다. 따라서 메인 스레드가 종료되면 함께 종료되면서 비동기 작업이 실행되지 않을 수 있기 때문에 메인 스레드를 대기시킨 것이다.
출력 결과를 보자.
processing: user2
result: user2
processing: user1
processing: user3
result: user1
result: user3
concatMap
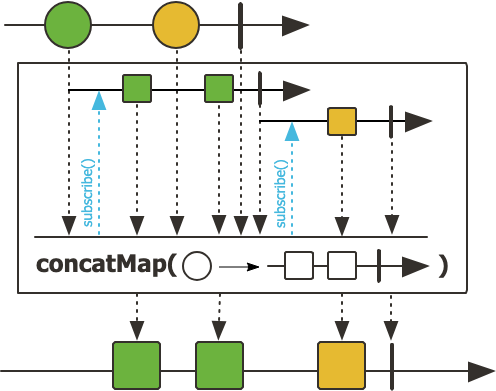
만약에 순서를 보장하고자 한다면 concatMap()을 활용하면 된다.
Flux.just("user1", "user2", "user3")
.concatMap(id -> Mono.just(id)
// ...
flatMap()은 내부적으로 여러 Publisher를 구독하고 합치기 때문에 병렬성으로 순서가 보장되지 않지만, concatMap()은 내부 Publisher에 대해 단일 구독으로 데이터를 처리하고 onComplete() 시그널을 기다린 다음에 다음 요소로 데이터를 처리하기 때문에 순서가 보장된다.
zip
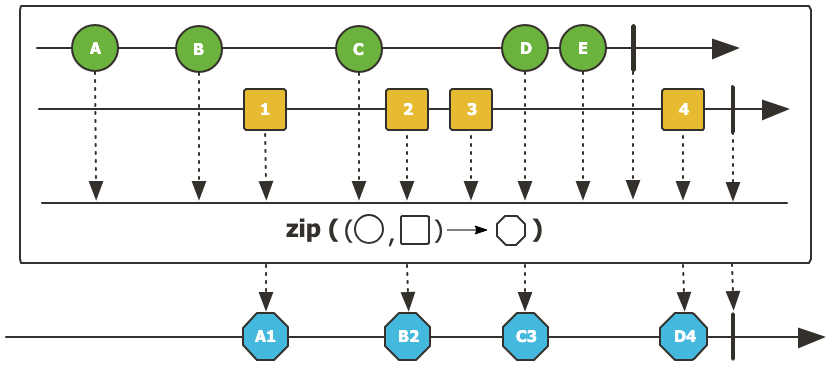
zip()은 둘 이상의 Flux나 Mono를 인덱스 기준으로 묶어서 동시에 방출하는 연산자이다.
Flux<String> fluxA = Flux.just("A1", "A2", "A3");
Flux<String> fluxB = Flux.just("B1", "B2", "B3");
Flux<Tuple2<String, String>> zipped = Flux.zip(fluxA, fluxB);
zipped.subscribe(t ->
System.out.println("Zipped: " + t.getT1() + ", " + t.getT2())
);
Tuple은 전달받은 Flux/Mono의 개수에 따라서 최대 8개까지 생성할 수 있으며 명명은 전달된 Flux/Mono의 개수가 N이라면 TupleN 이다. 즉 위의 경우에는 두 개의 Flux가 전달되었으므로 Tuple2가 사용되었다. 이후 해당 튜플에 대한 조회는 순서대로 getT1()으로 전달된 순서의 튜플을 조회할 수 있다. 실행 결과는 다음과 같다.
Zipped: A1, B1
Zipped: A2, B2
Zipped: A3, B3
그러면 성능은 어떨까? 여기서 만약에 fluxA가 1초 주기로 데이터를 방출하고, fluxB가 데이터를 10초 주기로 방출한다고 가정하면 zip()의 전체 성능은 10초 주기가 된다. 그리고 각 스트림의 끝나는 시점이 다르면 가장 빠르게 끝나는 스트림에 의해 조기 종료된다.
Flux<String> fluxA = Flux.just("A1", "A2");
Flux<String> fluxB = Flux.just("B1", "B2", "B3");
Flux<Tuple2<String, String>> zipped = Flux.zip(fluxA, fluxB);
zipped.subscribe(t ->
System.out.println("Zipped: " + t.getT1() + ", " + t.getT2())
);
이럴 경우 마지막 B3는 매핑될 fluxA의 요소가 존재하지 않기 때문에 방출되지 않는다.
concatWith
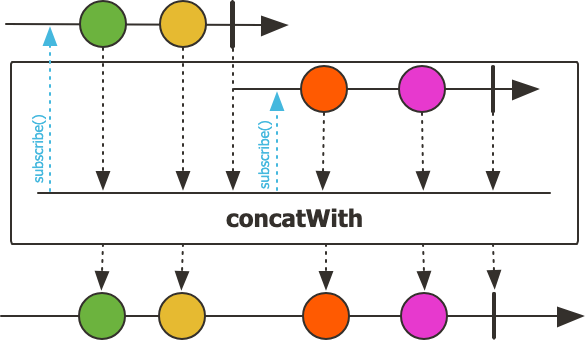
concatWith는 첫 번째 스트림이 onComplete() 시그널을 보낸 이후에 두 번째 스트림을 실행하도록 두 스트림을 순차적으로 연결하는 연산자다. 두 스트림의 요소 타입은 동일해야 하며, 앞선 스트림이 완료되어야만 뒤이어 오는 스트림이 실행된다. 따라서 SSE, WebSocket, Flux.interval() 같은 onComplete 시그널이 없는 무한 스트림과 함께 사용할 경우, 후속 스트림은 절대 실행되지 않는다.
Flux<String> fluxA = Flux.just("A1", "A2", "A3");
Flux<String> fluxB = Flux.just("B1", "B2", "B3");
Flux<String> concatenated = fluxA.concatWith(fluxB);
concatenated.subscribe(item -> System.out.println("Concat: " + item));
실행 결과는 다음과 같다.
Concat: A1
Concat: A2
Concat: A3
Concat: B1
Concat: B2
Concat: B3
concatWith()는 앞의 스트림이 끝나기 전까지 뒤 스트림을 절대 실행하지 않기 때문에, 자연스럽게 전체 처리 순서를 강제한다. 이 특성 때문에 flatMap()처럼 병렬 처리를 활용해야 할 상황에서 사용하면 성능이 크게 저하될 수 있다. 또한, 앞선 스트림에서 오류가 발생하면 그 즉시 종료되며, 뒤쪽 스트림은 실행되지 않는다는 점도 주의해야 한다.
mergeWith
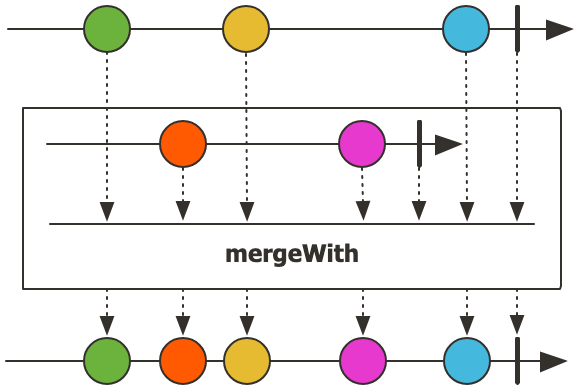
이 연산자는 두 스트림을 병렬로 섞는 연산자로, 병렬로 합친다는 특성 때문에 순서가 보장되지 않는다. 이를 확인하기 위해서 각각 Flux를 생성할 때 지연을 추가해서 확인해봤다.
Flux<String> fluxA = Flux.just("A1", "A2", "A3")
.delayElements(Duration.ofMillis(100));
Flux<String> fluxB = Flux.just("B1", "B2", "B3")
.delayElements(Duration.ofMillis(50));
Flux<String> merged = fluxA.mergeWith(fluxB);
merged.subscribe(System.out::println);
Thread.sleep(1000);
실행 결과는 다음과 같다.
B1
A1
B2
B3
A2
A3
fluxA와 fluxB의 각 데이터 요소가 하나의 Flux로 합쳐졌을 때 순서가 보장되지 않은 것을 볼 수 있다.
retry
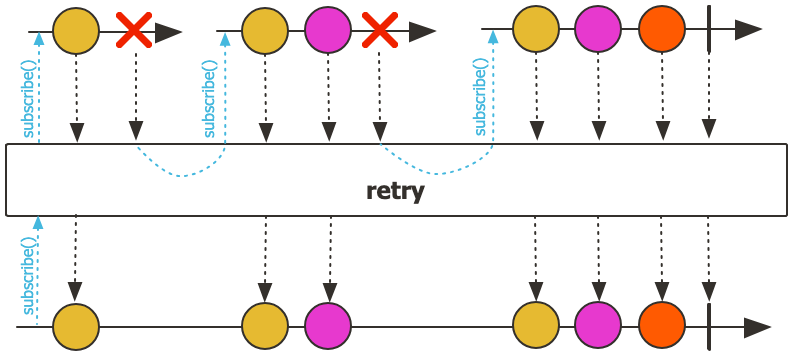
지정된 횟수만큼 재시도를 수행하도록 설정한다.
Flux<Integer> errorFlux = Flux.range(1, 5)
.map(i -> {
if (i == 3) throw new RuntimeException("Error at " + i);
return i * 10;
})
.retry(1) // 에러 발생 시 최대 1회 재시도
.onErrorResume(e -> {
System.err.println("Caught Error: " + e.getMessage());
return Flux.just(999); // 에러 발생 시 대체 스트림으로 999만 방출
});
errorFlux.subscribe(
data -> System.out.println("Result: " + data),
err -> System.err.println("Final Error: " + err),
() -> System.out.println("Done")
);
onErrorResume()는 에러 발생 시 대체 흐름을 제공하는 연산자이다. 대체 흐름을 제공하기 때문에 예외가 발생하지 않고 새로운 Flux 또는 Mono를 방출한다. 현재 코드에서는 1부터 5까지의 요소가 있고, 요소가 3일 때 의도적으로 RuntimeException을 던지도록 하고 코드를 실행해봤다.
Result: 10
Result: 20
Result: 10
Result: 20
Result: 999
i가 3일 때 RuntimeException이 발생하여서 처음부터 다시 시작한 것을 볼 수 있다. 이후 재시도에 명시된 재시도 횟수 1회를 초과하므로 onErrorResume()에 의해 대체 Flux가 반환되어 소비되었다.
스케줄링(Scheduler) 및 스레딩 모델
리액티브 파이프라인이 어떤 스레드 위에서 동작하는지는 비동기 처리 전략과 백프레셔 컨트롤에 큰 영향을 준다. Reactor의 스케줄러는 다양한 작업 특성(블로킹 I/O, CPU 바운드, 단일 스레드 순차 처리 등)에 최적화된 스레드풀을 제공한다.
단순히 비동기라고만 이해하면 데이터 흐름이 실제로 어느 스레드에서 처리되는지 파악하기 어렵고, 스레드 경합이나 블로킹 이슈 발생 시 문제 원인을 찾기 어려워진다. 따라서 주요 스케줄러와 subscribeOn/publishOn의 차이를 알아보도록 하자.
주요 스케줄러 종류
Schedulers.boundedElastic()- 용도: 블로킹 I/O(파일 입출력, 레거시 JDBC 호출 등) 작업에 적합한 스레드풀
- 특징: 필요할 때마다 최대 제한(기본 CPU 수 × 10)까지 스레드를 동적으로 생성하며, 일정 시간이 지나면 유휴 스레드를 회수
- 예시: DB 조회나 외부 REST API 호출같은 블로킹 지연 작업을 Reactor 스트림 안에서 수행할 때 사용
Schedulers.parallel()- 용도: CPU 바운드(계산, 암호화, 이미지 처리 등) 작업에 최적화된 스레드풀
- 특징: 기본적으로 CPU 코어 수만큼 고정된 워커 스레드를 생성
- 예시: 수치 연산이나 대량 데이터 병렬 처리같은 작업을 비동기로 처리할 때 사용
Schedulers.single()- 용도: 단일 스레드를 사용해 순차적으로 처리해야 하는 작업(예: 순서 보장이 중요한 경우)
- 특징: 내부적으로 하나의 스레드만 사용하며, 순차적 처리만 보장
- 예시: 순차적으로 로그를 기록하거나, 순서를 보장해야 하는 직렬화 작업에 활용
Schedulers.immediate()- 용도: 현재 스레드에서 즉시 실행(동기 실행)
- 특징: 별도 스레드풀을 사용하지 않고,
subscribe()를 호출한 동일 스레드에서 연산을 수행 - 예시: 테스트 환경이나 백프레셔 실험용으로만 제한적 사용
여기서 한 가지 의문이 생겼었는데 바로 블로킹 I/O 작업에 적합한 스레드 풀에서 동작한다면, WebFlux로 서버를 개발한다고 해도 동접자가 계속해서 늘어났을 때 결국 논 블로킹으로 서버의 병목은 결국 발생하는 것 아닌가? 하는 생각이었다.
하지만 이는 잘못된 생각이었다. 스케줄러는 리액터 내부에서 다양한 작업을 처리하기 위한 보조 스레드풀 관리자이며, WebFlux의 핵심은 메인 서버 스레드가 Netty의 이벤트 루프 기반으로 동작해 완전한 Non-Blocking을 제공한다는 점이다. 즉, 블로킹 I/O가 발생하더라도 이벤트 루프는 그 작업을 직접 수행하지 않고, 이를 boundedElastic과 같은 별도의 스케줄러로 위임하기 때문에 서버의 이벤트 루프 자체는 전혀 막히지 않는다.
정리하자면 WebFlux는 블로킹으로 인해 병목이 생길 수 있는 위치를 이벤트 루프에서 분리하여, Blocking I/O는 리액터 스케줄러에서 처리하고, 결과가 준비되면 다시 이벤트 루프에 전달해 클라이언트로 응답을 전송하는 구조이다. 이렇게 이벤트 루프는 항상 Non-Blocking을 유지하기 때문에, 동접자가 크게 늘어나더라도 서버의 처리 능력이 쉽게 감소하지 않고 높은 동시성을 유지할 수 있다.
subscribeOn / publishOn
스케줄러를 지정할 수 있는 연산자로, 데이터를 소비하는 시점과 데이터를 발행하는 시점에 맞춰서 적절한 스케줄러를 지정할 수 있게 해준다.
| 구분 | subscribeOn(Scheduler) | publishOn(Scheduler) |
|---|---|---|
| 적용 시점 | 구독 시점부터 전체 파이프라인에 영향을 미침 | 지정한 위치부터 이후 연산자에만 적용 |
| 역할 | 구독(데이터 요청) 단계 자체를 지정된 스케줄러로 이동 | 이후 연산자들을 지정된 스케줄러로 전환 |
subscribeOn(Scheduler)- 구독자가 구독을 시작할 때, 즉
Publisher.subscribe()호출 시점부터 지정된 스케줄러 위에서 전체 파이프라인 실행 - 주로 “항상 특정 스케줄러(예: 블로킹 I/O용 boundedElastic) 위에서 전체 스트림을 실행하고 싶을 때” 사용
- 구독자가 구독을 시작할 때, 즉
publishOn(Scheduler)- 스트림 내부에서 “해당 지점 이후로는 다른 스레드풀(예: parallel)에서 연산을 계속 수행하라”고 전환
- 서로 다른 연산자 그룹을 각기 다른 스케줄러에서 실행하고 싶을 때 유용
스케줄러 전환 예시
Flux.range(1, 5)
.map(i -> {
System.out.println("Map on Thread: " +
Thread.currentThread().getName()
);
return i * 2;
})
// 구독 시점부터 boundedElastic 스케줄러 사용
.subscribeOn(Schedulers.boundedElastic())
// 이후 연산자부터 parallel 스케줄러로 전환
.publishOn(Schedulers.parallel())
.doOnNext(i ->
System.out.println("Next on Thread: " +
Thread.currentThread().getName()
)
)
.subscribe();
Thread.sleep(1000);
위 코드 실행 시, map(...) 단계는 boundedElastic 스레드풀에서 실행되고, doOnNext(...) 단계부터는 parallel 스레드풀에서 실행된다. 이렇게 스케줄러를 적절히 전환하면, 블로킹 작업은 boundedElastic에서, 계산 작업은 parallel에서 처리하도록 역할별로 스레드풀을 분리할 수 있다.
실제로 이러한 스케줄러에서 동작하는지 확인하기 위해서 출력문으로 현재 스레드의 이름을 출력하도록 하였고, 그 결과는 다음과 같다.
Map on Thread: boundedElastic-1
Map on Thread: boundedElastic-1
Map on Thread: boundedElastic-1
Map on Thread: boundedElastic-1
Map on Thread: boundedElastic-1
Next on Thread: parallel-1
Next on Thread: parallel-1
Next on Thread: parallel-1
Next on Thread: parallel-1
Next on Thread: parallel-1
ConnectableFlux
때로는 구독자마다 새로운 데이터를 생성하는 Cold Publisher인 Flux를 여러 구독자가 동시에 같은 시점부터 같은 데이터를 공유하며 방출하는 Hot Publisher로 만들어야 하는 상황이 존재한다. 이때 publish() 연산자를 사용해 ConnectableFlux로 변환하고, connect()를 호출해 실제 방출 시점을 제어할 수 있다. 사용 방법은 다음과 같다.
Flux<T>에.publish()를 호출해ConnectableFlux<T>로 변환connect()를 호출해야만 데이터 방출이 시작됨- 이후 구독자들이
ConnectableFlux에 구독하면, 모두 같은 시점부터 데이터를 공유
ConnectableFlux<Long> connectable = Flux.interval(Duration.ofMillis(300))
.publish(); // Cold → Hot 전환
// 아직 방출 전이므로 아무도 데이터 수신하지 않음
connectable.connect(); // 실제 방출 시작
connectable.subscribe(i -> System.out.println("Subscriber1: " + i));
Thread.sleep(600);
connectable.subscribe(i -> System.out.println("Subscriber2: " + i));
Thread.sleep(900);
300ms 주기로 데이터를 방출하도록 ConnectableFlux를 만들었다. 그리고 총 1500ms 동안 데이터를 방출하도록 Thread.sleep()을 호출하였는데, 이렇게 처리하기 때문에 초기 값인 0부터 4까지 생산된다. 그리고 첫 번째 구독자의 구독 이후 600ms 동안 대기를 한 다음에 두 번째 구독자가 구독을 하도록 처리했다. 이렇게 처리하면 출력은 어떻게 되는지 확인해보자.
Subscriber1: 0
Subscriber1: 1
Subscriber1: 2
Subscriber2: 2 // Subscriber2는 이 시점부터 구독을 시작했다.
Subscriber1: 3
Subscriber2: 3
Subscriber1: 4
Subscriber2: 4
Cold Publisher와 Hot Publisher의 차이를 이해하면 데이터 방출 시점과 구독 시점을 명확히 설계할 수 있다. 특히 실시간 데이터나 사용자 이벤트를 다룰 때 Hot Publisher를 활용하고, 여러 구독자가 동시에 동일한 시퀀스를 받아야 할 때는 ConnectableFlux를 사용하면 효과적이다.
상황에 맞는 연결 설정
앞서 코드에서 작성한 connect() 이외에도 autoConnect()와 refCount()가 존재한다.
autoConnect
인자로 전달한 n명의 구독자가 모이면 자동으로 connect()를 호출하는 방식이다.
Flux<Long> flux = Flux.interval(Duration.ofMillis(300))
.publish()
.autoConnect(2); // 구독자 2명 모이면 connect()
flux.subscribe(v -> System.out.println("Sub1: " + v));
Thread.sleep(500);
flux.subscribe(v -> System.out.println("Sub2: " + v));
// 여기서 자동 connect() 발생 → 방출 시작
Thread.sleep(1000);
지정된 수 이상의 구독자가 모이지 않으면 connect()가 되지 않는 특성이 있다. 하지만 일단 connect()가 되면 Hot Publisher는 유지되며, 이는 구독자가 모두 사라져도 계속해서 유지된다. 이 방식은 WebSocket 브로드캐스트 준비 시점 통제 용도로 사용할 수 있다고 한다.
refCount
구독자 수가 n명 이상일 대만 Hot Publisher로 동작하고, 구독자가 n 미만으로 떨어지면 Hot Publisher가 종료되고 다시 Cold Publisher로 작동하는 방식이다.
Flux<Long> flux = Flux.interval(Duration.ofMillis(300))
.publish()
.refCount(2); // 구독자가 2명 이상일 때만 실행
Disposable sub1 = flux.subscribe(v -> System.out.println("Sub1: " + v));
Thread.sleep(500);
Disposable sub2 = flux.subscribe(v -> System.out.println("Sub2: " + v));
// 이 시점부터 interval 시작
Thread.sleep(800);
// 구독자 1명으로 줄어들면서 자동 정지
sub1.dispose();
Thread.sleep(500);
반응형 Flux로 n명 이상이 되면 새로운 Cold Publisher로 동작한다는 특성은 특정 기능을 실제로 여러 구독자가 동시에 사용할 때만 계산하거나 스트림을 유지하고 싶을 때 사용하면 좋다고 한다. 그 예시로 모니터링 스트림이 있을 수 있다. 실제 사용자가 없으면 모니터링 정보를 생산해봤자 의미가 없기 때문이다.
백프레셔
리액터도 리액티브 스트림 명세를 따르기 때문에 백프레셔가 설계되어 있다. 하지만 지금까지 백프레셔를 다루는 부분이 존재하지 않았다. 이는 Flux와 Mono가 기본적으로 백프레셔를 지원하기 때문이다. 일반적인 subscribe()는 내부적으로 LambdaSubscriber<T>의 onSubscribe()에 무제한으로 데이터를 요청한다.
// LambdaSubscriber
@Override
public void onSubscribe(Subscription s) {
if (Operators.validate(subscription, s)) {
// ...
else {
s.request(Long.MAX_VALUE);
}
}
}
하지만 이러면 결국 데이터가 무제한으로 공급될 수 있다는 건데 결국 백프레셔를 지원하지 않는 것 아닌가? 생각이 들었다. 하지만 이는 백프레셔라는 개념을 조금 혼동해서 그렇게 생각했던 것이었다. 다음 조건을 만족하면 백프레셔를 지원한다고 봐야 한다.
request(n)호출 시 n개 이하의 데이터만 생산request()호출 이전에는 데이터를 방출하지 않음- 요청 개수에 0 또는 음수에 대해서 예외 발생
위 정의에 따르면 Subscriber가 데이터를 무제한으로 받는다고 요청했을 뿐이고 Publisher는 백프레셔를 지원한다고 볼 수 있다. 백프레셔를 사용하지 않는 것이지 지원하지 않는 건 아니라는 것이다. 이렇게 무제한 요청을 받도록 한 이유는 무엇일까? 이는 기본적으로 다음과 같은 이유 때문이다.
실제 비즈니스 상황에서는 모든 값을 받는 소비자가 훨씬 많다.
HTTP 응답, 데이터베이스 조회 결과, 파일 스트림 등 소비자가 전체 데이터를 소비하는 경우가 훨씬 많다. 따라서 기본값으로 무제한을 선택한 것이다.
자동 백프레셔 전략도 이미 내장되어 있다.
리액터 내부적으로 다양한 백프레셔 전략을 제공한다.
onBackpressureBuffer()onBackpressureDrop()onBackpressureLatest()limitRate()
이를 정리하면 다음과 같다.
| 전략 | 버퍼 | 초과 시 | 특징 |
|---|---|---|---|
| onBackpressureBuffer | O | OverflowException | 생산자가 매우 빠를 때 저장하지만, 버퍼 관리 필요 |
| onBackpressureDrop | X | 즉시 폐기 | 리소스 아끼고 가장 단순 |
| onBackpressureLatest | X | 최신값만 유지 | UI 업데이트/센서 데이터에 매우 적합 |
| limitRate | 내부 요청 양 제한 | 없음 | 소비자가 안정적으로 흡수 가능 |
리액터에서의 백프레셔 직접 제어
만약에 백프레셔를 직접 구현해서 처리하고자 한다면 BaseSubscriber<T>를 상속해서 hookOnSubscribe()와 hookOnNext()를 재정의하면 된다.
class MySubscriber extends BaseSubscriber<Integer> {
@Override
protected void hookOnSubscribe(Subscription subscription) {
request(1);
}
@Override
protected void hookOnNext(Integer value) {
System.out.println("Got: " + value);
request(1);
}
}
해당 클래스를 다음과 같이 사용할 수 있다.
Flux<Integer> fastProducer =
Flux.range(1, 5) // 사실상 무한정 빨리 생산 가능
.doOnNext(i -> System.out.println("Produced: " + i));
fastProducer.subscribe(new MySubscriber());
Thread.sleep(5000);
실행 결과는 다음과 같다.
Produced: 1
Got: 1
Produced: 2
Got: 2
Produced: 3
Got: 3
Produced: 4
Got: 4
Produced: 5
Got: 5
Sink
때로는 애플리케이션 코드에서 직접 데이터를 푸시해야 하는 경우가 있다. 이러한 상황에서 리액터는 Sink API를 제공한다. 대표적인
Sinks.one()
Mono 형태의 단일값을 푸시한다.
Sinks.many().unicast()
단일 구독자만 허용하는 Hot Publisher이다. Publisher와 Subscriber 사이에 큐를 통해서 데이터가 전달되기 때문에 백프레셔를 고려해야 한다.
Sinks.many().multicast()
여러 구독자에게 동일 데이터를 브로드케스트한다. ConnectableFlux로 대체할 수 있다.
Sinks.many().replay()
새 구독자에게 과거 데이터를 재전송한다.
애플리케이션 자체적으로 Sink를 활용하여 각 구독자에게 데이터를 푸시하는 코드를 간단하게 작성해봤다.
Sinks.Many<String> sink = Sinks.many().multicast().onBackpressureBuffer();
Flux<String> flux = sink.asFlux();
flux.subscribe(v -> System.out.println("Sub1: " + v));
sink.tryEmitNext("Hello");
sink.emitNext("!!!", Sinks.EmitFailureHandler.FAIL_FAST);
sink.tryEmitNext("World");
flux.subscribe(v -> System.out.println("Sub2: " + v)); // 뒤늦게 구독
sink.tryEmitNext("!!!");
실행 결과는 다음과 같다.
Sub1: Hello
Sub1: !!!
Sub1: World
Sub1: !!!
Sub2: !!!
여기서 tryEmitNext()는 실패해도 예외를 던지지 않지만 emitNext()는 실패 시 즉시 예외를 발생하고 재시도에 관한 정책을 Sink.EmitFailureHandler에게 위임해야 한다. 현재는 가장 단순하게 실패하면 재시도 없이 바로 실패를 반환하는 구조로 작성되어 있고, 만약에 재시도를 처리하고자 한다면 다음과 같이 설정하면 된다.
sink.emitNext("!!!", EmitFailureHandler.busyLooping(Duration.ofSeconds(10)));
이는 10초동안 성공할 때 까지 재시도를 처리하라는 의미이다. 만약에 필요하다면 직접 정의해서 사용할 수도 있다.
AtomicInteger retryCount = new AtomicInteger(0);
EmitFailureHandler handler = (signalType, emitResult) -> {
if (emitResult == EmitResult.FAIL_NON_SERIALIZED &&
retryCount.incrementAndGet() < 10) {
return true; // 멀티스레드 충돌이면 재시도
}
return false; // 나머지는 실패
};
Spring WebFlux로 넘어가기 이전에 프로젝트 리액터에 대해서 학습하면 도움이 될 것 같아서 학습해서 정리해봤다. 처음 접하는 것을 학습해서 정리하는 것은 언제나 힘든 일인 것 같다.
댓글남기기