Spring WebFlux와 Spring Data R2DBC
Flow API와 프로젝트 리액터를 알아보았다. 이는 모두 Spring WebFlux를 사용하기 위해서 필요한 기초 지식들이었다. 그렇다면 이제 Spring WebFlux에 대해서 알아보도록 하자.
Spring WebFlux란?
Spring WebFlux는 Spring 5에서 도입된 리액티브 웹 프레임워크로, Project Reactor를 기반으로 한 논블로킹/비동기 프로그래밍 모델을 제공하며, 기본적으로 Reactor Netty 위에서 동작하지만 Undertow나 Servlet 3.1+ 컨테이너에서도 실행될 수 있다.
Netty
Netty는 Java NIO를 기반으로 설계한 비동기·이벤트 기반 네트워크 애플리케이션 프레임워크다. Java NIO는 기존의 IO API를 대체하기 위해 Java 1.4에서 도입된 I/O API이다. 논블로킹 I/O를 지원하기에 Java Non-Blocking I/O라고 많이들 이야기하지만, 엄밀하게 이야기한다면 Java의 기존 I/O를 대체했다는 의미로 Java New I/O라고 봐야한다.
핵심 컴포넌트
Netty의 핵심 컴포넌트는 무엇이 네트워크 연결을 대표하고, 누가 이벤트를 돌리고, 어디에 비즈니스 로직을 꽂는가로 나눠서 보면된다.
Channel
- 소켓/연결 자체를 추상화한 객체로, “이 클라이언트와의 TCP 연결 하나”를 표현한다고 보면 된다.
read,write,bind,connect같은 I/O 작업과, 연결 상태(열림, 닫힘 등) 및 옵션을 관리한다.
EventLoop / EventLoopGroup
- EventLoop는 하나의 스레드에서 여러 Channel의 I/O 이벤트를 돌리는 이벤트 루프(reactor) 역할을 한다.
- EventLoopGroup은 이런 EventLoop들의 묶음이고, Boss(accept 담당) / Worker(I/O 담당) 같은 형태로 나뉘어 많은 연결을 적은 스레드로 처리한다.
ChannelHandler
- 애플리케이션 입장에서 가장 중요한 컴포넌트로, 인바운드/아웃바운드 데이터 처리 로직(파싱, 비즈니스 로직 호출, 예외 처리 등)을 담는 컨테이너다.
- 인바운드용(
ChannelInboundHandler), 아웃바운드용(ChannelOutboundHandler) 인터페이스를 통해 “데이터 읽힘”, “쓰기 요청” 같은 이벤트마다 콜백 메서드가 호출된다.
ChannelPipeline
- 여러 ChannelHandler를 체인 형태로 연결한 구조로, 연결 하나당 하나의 파이프라인이 존재한다.
- 인바운드 이벤트는 앞에서 뒤로, 아웃바운드 이벤트는 뒤에서 앞으로 흐르면서 핸들러들을 거치며 처리된다.
ByteBuf
- Netty가 제공하는 바이트 버퍼 구현체로, Java NIO
ByteBuffer보다 편리한 읽기/쓰기 인덱스 관리와 다양한 헬퍼 메서드를 제공한다. - 네트워크로 들어오고 나가는 실제 바이트 데이터는 대부분 ByteBuf를 통해 다루게 된다.
Bootstrap / ServerBootstrap
- Netty 애플리케이션을 띄울 때 사용하는 설정 빌더로, EventLoopGroup, Channel 타입(NioServerSocketChannel 등), 파이프라인 초기화 핸들러 등을 등록한다.
- 클라이언트 쪽은
Bootstrap, 서버 쪽은ServerBootstrap을 써서 “어떤 스레드 모델 + 어떤 채널 + 어떤 파이프라인으로 서버를 돌릴지”를 한 번에 구성한다.
Reactor와 Netty의 이벤트 루프 차이
Netty의 EventLoop는 커널의 Selector를 돌면서 소켓의 accept, read, write 같은 네트워크 I/O 이벤트를 처리하는 루프다. 각 EventLoop는 하나의 스레드에서 여러 Channel을 관리하고, 발생한 이벤트를 ChannelPipeline의 핸들러들에게 전달한다.
반대로 Project Reactor의 이벤트 루프/스케줄러는 Flux·Mono 체인 같은 리액티브 연산을 어떤 스레드에서 언제 실행할지 결정하는 실행 모델이다. Schedulers.single(), parallel(), boundedElastic() 같은 스케줄러가 내부적으로 스레드/큐를 관리하면서 map, flatMap, filter 같은 연산을 비동기적으로 실행한다.
따라서 WebFlux + Reactor Netty 조합에서는 Netty EventLoop가 네트워크 I/O를 담당하고, 그 위에서 Reactor 스케줄러가 비즈니스 로직이 담긴 리액티브 파이프라인 실행을 담당하는 구조로 동작한다.
정리하자면 Netty는 소켓·바이트 레벨, Reactor는 데이터 스트림·비즈니스 로직 레벨을 책임진다고 정리할 수 있다.
Spring WebFlux 도입 전 알아야 할 의사결정 기준
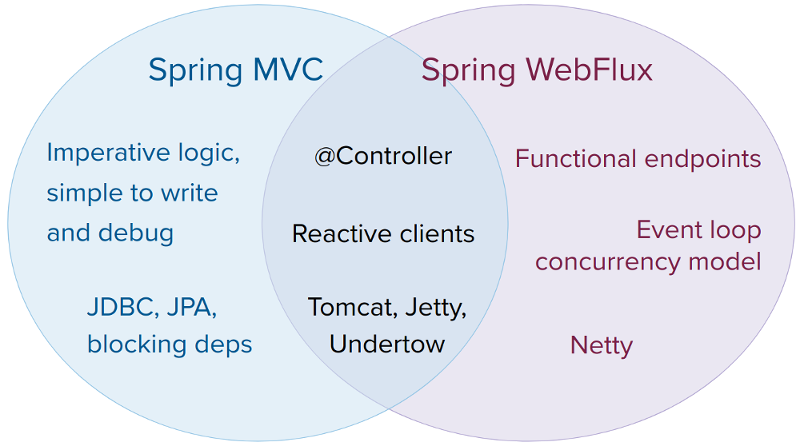
Spring MVC와 Spring WebFlux 중에서 무엇을 선택해야 하는지 공식문서에서 다음과 같이 언급한다.
- 이미 잘 작동하는 Spring MVC 애플리케이션이 있다면 굳이 바꿀 필요 없다.
Spring MVC는 코드 가독성과 디버깅이 쉽고 대부분의 라이브러리가 블로킹 기반이라 MVC와 잘 맞는다.
- 비동기/논블로킹 웹 스택을 찾고 있다면 선택해봐라.
Node.js처럼 이벤트 기반의 논블로킹 실행 모델을 사용하며, Netty·Tomcat·Jetty 등 다양한 서버 선택이 가능하다. 또한 Spring MVC와 동일한 어노테이션 기반 컨트롤러도 사용할 수 있어 진입장벽이 낮다.
- 함수형 스타일, 경량 프레임워크를 원한다면 WebFlux Functional API를 활용해라
Java 8 람다나 Kotlin과 잘 맞고 작은 마이크로 서비스나 간단한 API에 적합하다.
- MSA라면 MVC + WebFlux를 섞어 쓸 수 있다.
예를 들어 Gateway만 WebFlux를 사용하거나 부하가 심할 것으로 예측되는 웹소켓 게임 서비스 등에 WebFlux를 활용하라는 것 같다.
- 블로킹 API를 쓴다면 WebFlux는 오히려 손해다.
JPA나 JDBC는 모두 블로킹 방식으로 동작하므로 논블로킹의 이점을 버리게 된다는 것으로, WebFlux를 활용하려면 관련 라이브러리들이 모두 논블로킹 방식으로 동작해야 한다는 것을 의미한다.
- Spring MVC에서도 WebClient를 쓸 수 있다.
서버에서 원격 API 호출이 많은 경우 WebClient를 활용해서 여러 외부 API를 병렬로 처리하여 지연 시간이 큰 호출에서 유리하다.
- 팀 규모가 크면 WebFlux 도입 난이도가 높다.
논블로킹, 함수형, 리액티브 패러다임을 학습해야 하기 때문에 러닝커브가 존재한다.
그리고 마지막으로 다음 문장으로 마무리된다.
다양한 애플리케이션에서 이러한 전환은 불필요할 것으로 예상된다.
정리하자면 대부분의 경우 MVC + WebClient면 충분하다. WebFlux는 필요할 때만 선택하는 것이 스프링 팀의 공식적인 입장이다.
성능
‘비동기 + 논블로킹’이라는 특성 때문에 WebFlux가 항상 더 빠를 것이라 생각하지만, 실제로는 그렇지 않다. Spring MVC가 감당 가능한 범위의 트래픽에서는 WebFlux가 오히려 약간 더 느릴 수 있다. 매 요청마다 Mono/Flux 파이프라인을 생성하는 오버헤드가 존재하기 때문이다.
그러나 핵심은 속도가 아니라 확장성이다. WebFlux는 요청마다 스레드를 점유하지 않기 때문에, MVC가 스레드 풀 한계에 도달해 오류가 발생하는 구간에서도 정상적으로 버티며 일관된 처리량을 유지한다. 즉 MVC는 빠르지만 무너질 수 있는 구조, WebFlux는 느릴 수 있지만 무너지지 않는 구조라고 보는 것이 더 가깝다. 그래서 일정 수준 이상의 동시성이 요구되는 상황에서는 WebFlux가 더 높은 안정성과 처리량을 보여주게 된다.
Spring Data R2DBC
앞서 살펴본 것처럼 JPA나 JDBC처럼 블로킹 방식의 데이터 접근 기술과 WebFlux를 함께 사용하면 논블로킹의 이점을 제대로 살리지 못한다. 결국 요청 처리 과정의 한 축을 블로킹 I/O가 막아버리면, WebFlux의 스레드 효율성과 확장성은 크게 손상된다.
하지만 웹 애플리케이션과 RDBMS는 대부분의 실서비스에서 뗄 수 없는 관계이며, 데이터 접근 계층이 논블로킹으로 동작하지 않는다면 WebFlux 기반 애플리케이션의 전체 체인이 끊기게 된다. 이러한 이유로 스프링 진영은 비동기·논블로킹 데이터베이스 접근을 위한 표준인 R2DBC를 기반으로, Spring Data R2DBC라는 전용 프레임워크를 제공한다.
참고로 R2DBC는 기존의 JDBC나 JPA처럼 스레드가 블로킹되는 방식이 아니라, 리액티브 스트림을 기반으로 비동기적으로 데이터베이스와 통신하기 위해 만들어진 명세다. Spring Data R2DBC는 이 표준을 구현한 스프링 생태계의 데이터 접근 기술이며, 다음과 같은 데이터베이스를 지원한다.
- H2
- Oracle
- MySQL
- MariaDB
- Microsoft SQL Server
- jasync-sql MySQL
- Postgres
Spring Data JPA와의 비교
기존에 활용하는 Spring Data JPA와 비교해보면 가장 큰 차이점은 바로 지연 로딩, 엔티티 연관관계 매핑, 영속성 컨텍스트 같은 ORM 기능이 없다는 것이다. 따라서 다음과 같은 활용은 불가능하다.
- 연관관계 없음
- 엔티티 상태 추적 없음
- 1차 캐시 없음
- 변경 감지 없음
단순하게 객체를 데이터베이스와 매핑하는 역할을 하는 도구라고 보면 된다. 따라서 JOIN이나 서브쿼리를 통해 여러 테이블을 종합해서 하나의 데이터를 만드는 경우에는 직접 쿼리를 작성하고 해당 데이터를 매핑할 객체를 설계해야 한다.
그래도 트랜잭션 관련 기능은 내부 구현체는 TransactionalOperatorImpl로 다르지만 단순하게 @Transactional로 명시적으로 선언하는 방식을 사용할 수 있기 때문에 JPA와의 차이점만 숙지해두면 될 것 같다.
활용 방법
Spring Data R2DBC를 활용하는 방법은 상황에 따라서 다르다고 볼 수 있다. 만약에 단순한 CRUD 기반의 작업이라면 ReactiveCrudRepository<T, ID>나 ReactiveSortingRepository<T, ID>를 활용하면 기존의 JpaRepository<T, ID>를 활용하는 것 처럼 간단한 save()를 지원하며, findById()같은 쿼리 메서드를 정의할 수도 있다. 그리고 @Query 같은 어노테이션으로 쿼리를 직접 작성할 수도 있다.
하지만 복잡한 쿼리라면 이야기가 달라진다. 연관관계가 없기 때문에 직접 쿼리를 작성해야 하는데 이런 복잡한 쿼리를 @Query로 작성하다보면 쿼리 문자열이 길어지고 유지보수가 어려워질 뿐만 아니라, JOIN·GROUP BY·서브쿼리 같은 고급 쿼리를 표현하기가 제한적이다. 특히 여러 테이블을 조합해 하나의 DTO로 매핑해야 하는 경우에는 Repository 레이어에서 처리하기가 비효율적이다.
이러한 상황에서는 보통 R2dbcEntityTemplate 또는 DatabaseClient를 직접 활용하여 SQL을 명시적으로 작성한다. 이 방식은 SQL의 유연함을 그대로 사용할 수 있어 복잡한 JOIN이나 조건 조합을 처리하기 용이하며, 조회 결과를 원하는 형태의 DTO나 POJO로 매핑하기도 쉽다.
실습
간단한 INSERT 기능을 레포지토리와 R2dbcEntityTemplate를 활용해서 한 번 만들어보자. 데이터베이스 스키마와 객체는 다음과 같다.
CREATE TABLE IF NOT EXISTS post (
`no` INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
`title` VARCHAR(100) NULL,
`content` TEXT NULL,
`created_at` TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP
);
no와 created_at이 기본값을 가지는 컬럼이므로 이 점에 유의해서 다음과 같이 엔티티를 만들었다.
@Table("post")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Post {
@Id
private Integer no = null;
private String title;
private String content;
@Column("created_at")
@CreatedDate
private LocalDateTime createdAt = null;
public Post(String title, String content) {
this.title = title;
this.content = content;
}
}
이제 활용 방법 예시 코드를 보도록 하자.
레포지토리 활용
public interface PostRepository extends ReactiveCrudRepository<Post, Integer> {
}
이렇게 ReactiveCrudRepository를 상속받기만 하면 된다. 간단하게 테스트 코드도 작성해봤다.
@ActiveProfiles("test")
@DataR2dbcTest
@Import(R2dbcAuditingConfiguration.class)
class PostRepositoryTest {
@Autowired
private PostRepository postRepository;
@BeforeEach
void setUp() {
postRepository.deleteAll()
.block();
}
@Test
@DisplayName("사용자가 게시판에 글을 작성하면 데이터베이스에 저장된다.")
void postSaveTest() {
// given
Post post = new Post("title", "content");
// when
Mono<Post> save = postRepository.save(post);
// then
StepVerifier.create(save)
.expectNextMatches(p ->
p.getNo() != null && p.getCreatedAt() != null
)
.verifyComplete();
}
}
저장이 완료되면 Spring Data R2DBC는 MappingR2dbcConverter라는 객체를 통해 내부적으로 반환된 ID값을 가지는 엔티티를 생성하기 위해서 Setter나 생성자, 또는 리플랙션을 통해 삽입한다. 당연히 이 과정에서 ID값을 가지는 필드를 알아야 하기 때문에 PK에 해당하는 필드에@Id를 명시해야 한다.
사실 이 과정을 디버깅하면서 그 과정을 직접 확인하면서 더 쓸만한 부분이 있나 찾아봤는데, 직접 디버깅을 해보니 수 많은 콜백과 프록시들이 거치면서 너무 파악하기 어려웠다. 그냥 이 정도로만 알고 넘어가면 될 것 같다.
R2dbcEntityTemplate 활용
위와 같은 기능을 하는 쿼리를 작성하려면 어떻게 해야할까? 간단한 기능이라서 사실 별 차이 없지만 R2dbcEntityTemplate는 QueryDSL 처럼 메서드를 활용해서 쿼리를 작성할 수 있다. 공식 문서의 예시를 살펴보자.
Mono<Person> first = template.select(Person.class)
.from("other_person")
.matching(query(where("firstname").is("John")
.and("lastname").in("Doe", "White"))
.sort(by(desc("id"))))
.one();
이를 통해 기본적인 SQL 문법은 모두 메서드로 지원하는 것을 알 수 있다. 따라서 다음과 같이 작성하면 된다.
@Repository
@RequiredArgsConstructor
public class CustomPostRepository {
private final R2dbcEntityTemplate template;
public Mono<Post> customSave(Post post) {
return template.insert(post);
}
}
이를 테스트한 코드는 다음과 같다.
@SpringBootTest
@ActiveProfiles("test")
class CustomPostRepository {
@Autowired
private CustomPostRepository postRepository;
@Test
@DisplayName("사용자가 게시판에 글을 작성하면 데이터베이스에 저장된다.")
void postSaveTest() {
// given
Post post = new Post("title", "content");
// when
Mono<Post> save = postRepository.customSave(post);
// then
StepVerifier.create(save)
.expectNextMatches(p ->
p.getNo() != null && p.getCreatedAt() != null
)
.verifyComplete();
}
}
여기서 @DataR2dbcTest로 테스트를 진행하면 테스트가 실패하는데, 그 이유는 해당 어노테이션이 슬라이스 테스트 용도로 Repository<T, ID>를 상속한 레포지토리와 R2dbcEntityTemplate 정도만 활성화되기 때문이라고 한다. @Repository는 레포지토리라는 것을 명시하기 위해서 붙은 것이고 내부적으로는 결국에는 일반적인 스프링 빈이기 때문에 해당 테스트가 실패하는 것으로 보인다. 따라서 R2dbcEntityTemplate만 활용해서 레포지토리를 작성하고 테스트할 때에는 @SpringBootTest를 명시해야 테스트가 정상적으로 진행된다.
Custom Repository 패턴 적용
R2dbcEntityTemplate를 활용한 복잡한 쿼리를 가진 기능을 개발할 때, 해당 템플릿 객체를 활용한 클래스에 별도로 @SpringBootTest를 명시하고 단위 테스트를 진행하거나 이 레포지토리를 주입해서 처리하려면 좀 번거로울 것 같다. 하나의 인터페이스에서 복잡한 쿼리를 작성한 별도 클래스를 활용할 수 있을까?
이 방법을 생각하다가 QueryDSL을 활용할 때 처럼 별도 인터페이스를 만들어 거기에 추상 메서드를 정의하고, 해당 인터페이스 구현체에 R2dbcEntityTemplate를 활용하는 식으로 만들면 될 것 같다고 생각했다. 코드를 보자.
public interface CustomPostRepository {
Mono<Post> customSave(Post post);
}
@RequiredArgsConstructor
public class CustomPostRepositoryImpl implements CustomPostRepository {
private final R2dbcEntityTemplate template;
@Override
public Mono<Post> customSave(Post post) {
return template.insert(post);
}
}
이렇게 구현한 다음에 ReactiveCrudRepository를 상속한 레포지토리에 추가 상속을 시키면 된다.
public interface PostRepository extends ReactiveCrudRepository<Post, Integer>,
CustomPostRepository {
}
레포지토리를 테스트하는 코드에서 customSave()로 교체한 다음 테스트를 통과하는 것을 확인했다.
Spring WebFlux에서 코드를 작성하는 방법은 사실 Project Reactor에서 실습한 코드와 크게 다를 것 없기 때문에 이번 포스팅은 Spring WebFlux가 무엇인지 간단하게 알아보고 선택할 때의 참고사항, 그리고 가장 많이 활용하는 관계형 데이터베이스를 Spring WebFlux에서 활용할 때 어떤 의존성을 사용해야 하는 지 알아보았다.
간단하게 게시판을 구현해봤는데 확실히 뭔가 리액티브 페러다임이란 게 많이 어려운 것 같다. 기능 구현 자체는 쉬운데 실제로 AI에게 이 코드가 어떤지 의견을 물어보면 리팩터링할 것들이 우수수 쏟아지는 것을 보며 개념은 알기 쉬워도 제대로 활용하기 까지는 많은 시간이 걸릴 것 같다는 생각이 들었다.
참고자료
비동기 서버에서 이벤트 루프를 블록하면 안 되는 이유 2부 - Java NIO와 멀티플렉싱 기반의 다중 접속 서버
댓글남기기