서버에 업로드된 파일을 저장하는 방법
파일 업로드 처리
개발을 하다보면 클라이언트에서 전송한 파일을 서버에서 적절하게 처리해야 할 때가 있다. 문서나 사진, 동영상 같은 파일은 스프링 부트에서 어떻게 처리하는 지 알아보도록 하자.
데이터베이스에 저장
이미지를 바이트 배열로 변환한 다음에 저장하는 방법이다. 하지만 이 방법은 절대로 사용해서는 안된다. 그 이유는 다음과 같다고 한다.
- 데이터 베이스 쿼리 속도가 느려질 수 있음
- 데이터 베이스가 차지하는 용량이 커져서 관리가 어려워짐
- 파일을 저장하고, 제공하는 것이 난해해짐
물론 이는 서비스의 크기에 따라서 달라진다고 하지만 일반적으로 비추천하는 방법인 것은 분명하다. 이 부분에 대해서 더 알아보고 싶다면 참고자료에 첨부해둔 두 사이트를 방문해보는 것을 추천한다.
서버 시스템에 저장
서버의 시스템에 저장한 다음에 이를 정적파일로 서빙하는 것은 서버의 용량이 충분하다고 가정했을 때 괜찮은 방법이다. 나 역시 작은 프로젝트를 할 때는 항상 이 방법을 사용했다. 흐름은 다음과 같다.
- 클라이언트가
{서버주소}/upload를multipart/form-data형식으로 파일을 담아서 POST 호출 - 서버에서 파일을 시스템에 저장
- 클라이언트에게 파일에 접근이 가능한 경로를
Location헤더로 반환
내 로컬 시스템은 윈도우이므로 나는 클라이언트로부터 파일 업로드 요청을 받으면 C://blog라는 것에 파일을 저장하고, 해당 파일에 접근할 수 있는 경로를 헤더에 담기로 하였다.
사전 설정
application.yml 파일에 다음과 같이 설정하도록 하자.
spring:
application:
name: blog
servlet:
multipart:
max-request-size: 150MB # (1) 전체 HTTP 요청의 최대 크기 제한 (멀티파트 포함)
max-file-size: 100MB # (2) 단일 파일 업로드의 최대 크기 제한
정적 파일 핸들러 추가
이를 위해서 스프링에서는 시스템 내부에 존재하는 정적 파일을 처리할 수 있게 지원해준다. WebMvcConfigurer 객체를 구현하면 addResourceHandlers를 재정의할 수 있는데, 여기서 다음과 같이 설정해주면 된다.
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
WebMvcConfigurer.super.addResourceHandlers(registry);
registry.addResourceHandler("/files/**")
.addResourceLocations("file:///C://blog/");
}
}
이러면 이제 {서버 주소}/files/를 통해 접근을 하게 되면 C://blog/ 경로에 접근하게 되는 것과 마찬가지라고 생각하면 된다.
컨트롤러 및 서비스 정의
사용자 요청을 받고 처리하기 위해 컨트롤러와 서비스를 정의하자. 스프링에서는 MultipartFile 이라는 객체를 통해서 사용자가 업로드한 파일을 손쉽게 다룰 수 있도록 지원해주기 때문에 이 객체를 활용하면 손쉽게 파일을 저장할 수 있다.
컨트롤러
@RestController
@RequiredArgsConstructor
public class RequestController {
private final FileService fileService;
@PostMapping("/upload")
public ResponseEntity<ResponseEntityHelper<Void>> upload(
@RequestPart MultipartFile file
) {
return ResponseEntity
.created(URI.create(fileService.saveFile(file)))
.build();
}
}
서비스
서비스에서는 원본 파일의 이름을 받으면 확장자를 추출하여 현재 시간.확장자 이름의 형식으로 저장하도록 할 것이다.
@Service
public class FileService {
public String saveFile(MultipartFile file) {
String rootPath = Paths.get("C:", "blog").toAbsolutePath().toString();
String fileName = file.getOriginalFilename();
String ext = fileName.substring(fileName.lastIndexOf("."));
String newFileName = System.currentTimeMillis() + ext;
try {
file.transferTo(new File(rootPath + File.separator + newFileName));
return newFileName;
} catch (Exception e) {
return null;
}
}
}
MultipartFile의 transferTo() 메소드를 사용하여 시스템에 파일을 저장할 수 있다.
테스트
그럼 이제 테스트를 해보자. 테스트를 위해서 도커 이미지를 서버에 업로드 할 것이다.
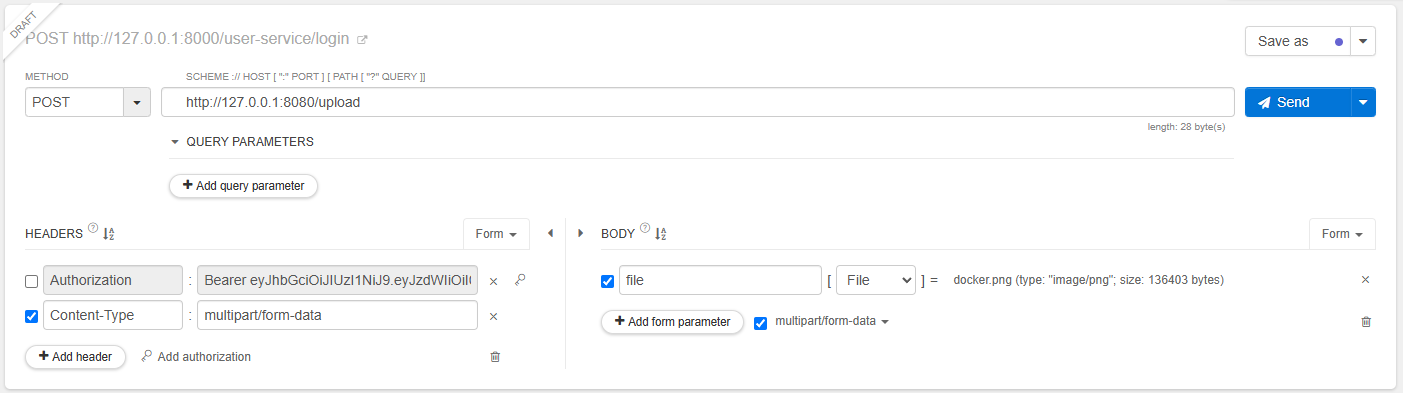
업로드에 성공하면 다음과 같은 응답이 반환된다.
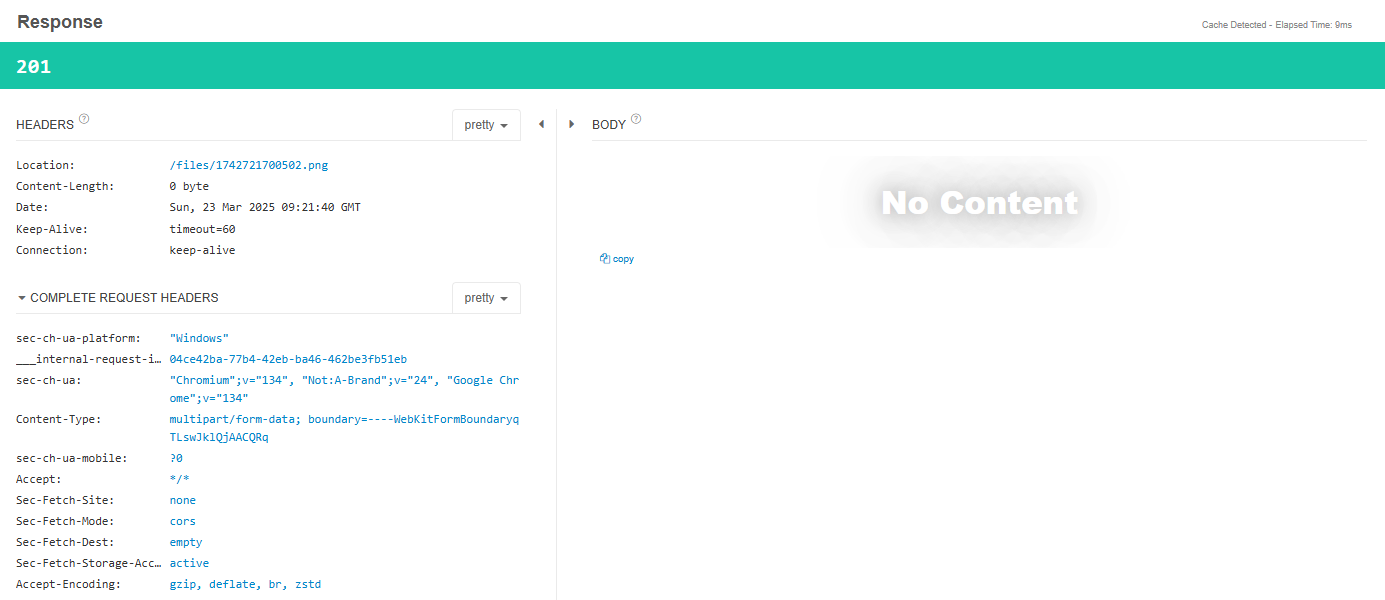
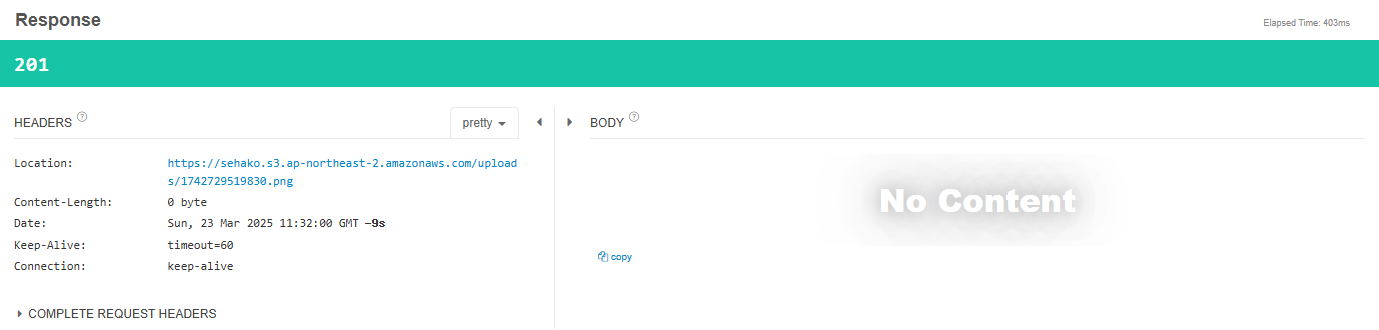
잘 보면 Location에 도커 이미지가 어떻게 저장되었는 지 볼 수 있을 것이다. 그렇다면 http://localhost:8080/files/1742721700502.png로 접속하면 실제로 도커 이미지를 볼 수 있을 것이다. 데이터베이스에 저장할 때도 서버 주소를 제외한 값 만 저장하면 된다. 즉 위의 경우에는 files/1742721700502.png를 저장하게 되는 것이다.
AWS S3에 저장
마지막으로 AWS에서 제공하는 S3 저장소를 활용하는 방법이 있다. 앞서 보았던 시스템에 파일을 저장하는 방법은 한 가지 문제점이 존재하는데, 클라이언트가 업로드한 파일이 서버 시스템에 저장되기 때문에 시스템 저장소의 용량이 부족해질 수 있는 문제가 존재한다.
또한 서버 시스템의 저장소에 문제가 생겼을 경우 클라이언트가 업로드한 파일이 유실될 수 있는 문제점도 있고, 만약에 서버 시스템을 여러 대 사용할 경우에 클라이언트가 저장한 파일을 어떻게 관리해야 하는가에 대한 고민도 생긴다.
하지만 S3는 요금만 충분하다면 용량을 무제한으로 사용할 수 있고, AWS의 설명을 인용하자면 99.999999999% (11 9’s)의 내구성을 자랑하여 안전하다. 또한 서버 시스템을 여러 대 사용하여도 S3가 중앙 저장소 역할을 하기 때문에 파일 관리도 고민할 필요가 없어진다.
S3 버킷 생성
먼저 파일을 저장해둘 S3 버킷을 생성하도록 하자.

여기서 퍼블릭 엑세스 차단을 해제해야 한다.
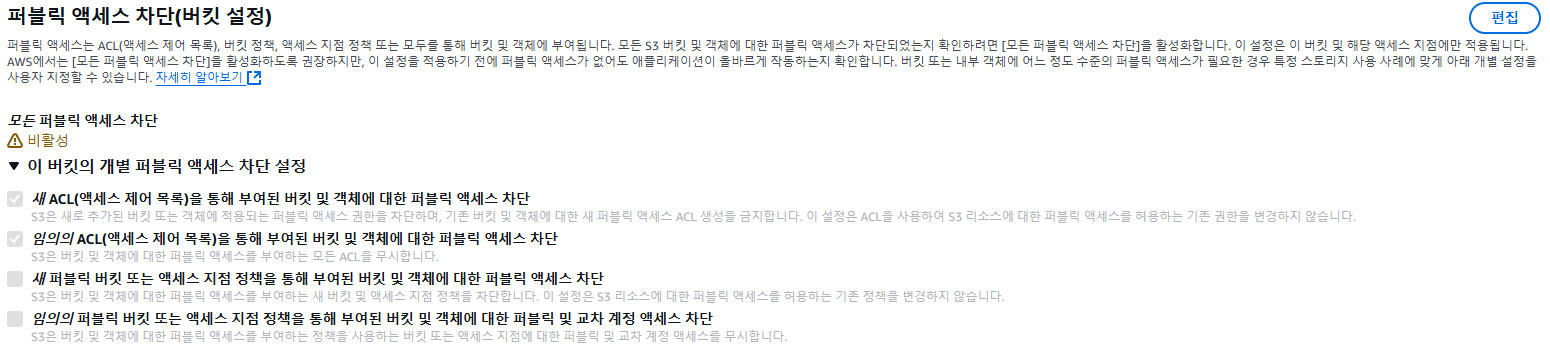
그리고 버킷 정책을 다음과 같이 작성하자.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadAccessToUploads",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::YOUR_BUCKET_NAME/uploads/*"
}
]
}
이러면 uploads에 저장된 모든 파일에 대해서 모든 클라이언트가 접근이 가능하다.
IAM 생성
파일 업로드를 위해서는 S3에 접근할 수 있는 권한을 가진 사용자가 필요하다 AWS IAM에서 다음과 같이 사용자를 생성하도록 하자.
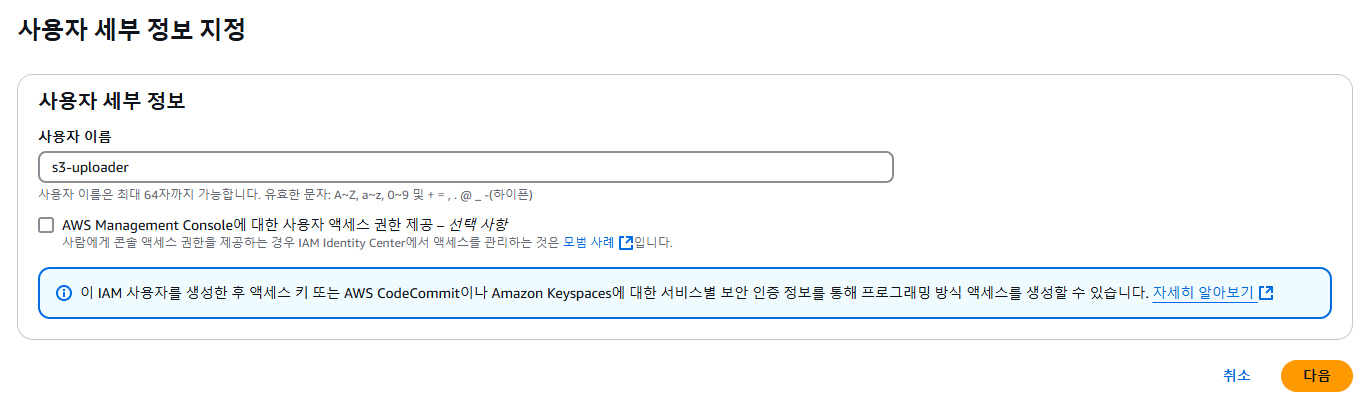
사용자를 생성한 다음에는 엑세스 키를 발급받아야 한다. 엑세스 키는 AWS 외부에서 실행되는 어플리케이션을 사용 사례로 선택하자.
사용자가 생성되면 엑세스 키와 비밀 엑세스 키를 발급받는다.
스프링 부트 설정
이제 스프링부트에서 AWS S3에 접근할 수 있도록 설정해주자. 다음 의존성이 필요하다.
implementation 'org.springframework.cloud:spring-cloud-starter-aws:2.2.6.RELEASE'
그리고 application.yml에 다음과 같이 설정하도록 하자.
cloud:
aws:
credentials:
access-key: ${AWS_ACCESS_KEY}
secret-key: ${AWS_SECRET_KEY}
region:
static: ap-northeast-2
stack:
auto: false
이때 stack.auto는 ec2의 정보를 가져오는 설정이라고 한다. 우리는 로컬에서 실행하므로 필요 없기 때문에 false로 설정해주자. AWS_ACCESS_KEY와 AWS_SECRET_KEY는 앞서 발급받은 IAM 사용자의 키 이다. 이를 환경변수로 설정한 것이다.
S3 스프링 빈 생성
S3에 접근하기 위해서는 AmazonS3 스프링 빈을 생성해야 한다. 내가 찾아봤던 레퍼런스는 설정 파일 하나로 어떻게 끝내는 참고자료도 있던데 같은 의존성 버전임에도 S3를 설정으로 접근하는 부분이 나는 없었다. 따라서 다른 자료를 참고하였다.
@Configuration
public class S3Config {
@Value("${cloud.aws.credentials.access-key}")
private String accessKey;
@Value("${cloud.aws.credentials.secret-key}")
private String secretKey;
@Value("${cloud.aws.region.static}")
private String region;
@Bean
public AmazonS3 amazonS3() {
AWSCredentials credentials = new BasicAWSCredentials(accessKey, secretKey);
return AmazonS3ClientBuilder.standard()
.withRegion(region)
.withCredentials(new AWSStaticCredentialsProvider(credentials))
.build();
}
}
컨트롤러 및 서비스 정의
참고로 요청에 대한 흐름은 앞선 시스템에 저장하는 것과 마찬가지이다. 파일을 저장하는 장소가 시스템에서 S3 버킷으로 바뀐 것 뿐이다.
컨트롤러
@RestController
@RequiredArgsConstructor
public class RequestController {
private final FileService fileService;
@PostMapping("/upload")
public ResponseEntity<ResponseEntityHelper<Void>> upload(
@RequestPart MultipartFile file
) {
return ResponseEntity
.created(URI.create(fileService.saveFileToAWS(file)))
.build();
}
}
서비스
@Slf4j
@Service
@RequiredArgsConstructor
public class FileService {
private final AmazonS3 amazonS3;
public String saveFileToAWS(MultipartFile file) {
String fileName = file.getOriginalFilename();
String ext = fileName.substring(fileName.lastIndexOf("."));
String newFileName = System.currentTimeMillis() + ext;
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentLength(file.getSize());
metadata.setContentType(file.getContentType());
try {
amazonS3.putObject(new PutObjectRequest(
"sehako",
"uploads/"+ newFileName,
file.getInputStream(),
metadata)
);
} catch (Exception e) {
e.printStackTrace();
return null;
}
return amazonS3.getUrl("sehako", "uploads/" + newFileName).toString(); // 업로드된 파일의 URL 반환
}
}
테스트
이제 테스트를 해보면 Location 헤더에 aws s3에 접근할 수 있는 경로가 나올 것이다.
최근에 새로 시작한 프로젝트에서는 스프링 Cloud를 이용한 MSA를 구축해보고 있다. 이번 프로젝트에서는 개발 보다는 MSA 구축과 로깅, 모니터링 부분을 한 번 해보고자 한다.
참고자료
Why Storing Files in the Database Is Considered Bad Practice
댓글남기기