실시간 채팅 개발 - 이벤트와 읽음 처리
카카오톡처럼, 채팅방에 메시지를 보내면 현재 채팅방에 존재하는 사람들을 제외한 n명의 사람들이 메시지를 읽지 않았다는 기능을 구현하고자 한다. 앞으로 간단하게 읽음 처리라고 하겠다.
데이터베이스 설계
저번 포스팅에서 설계한 ERD를 기반으로 적절하게 변경해보자.
메시지 별 읽지 않은 클라이언트 관리
클라이언트가 메시지를 보낼 때 전체 채팅방 클라이언트 수 - 현재 접속중인 클라이언트 수를 한 결과를 저장하는 컬럼을 각 채팅 메시지마다 두고, 채팅방에 접속한 클라이언트를 관리하는 테이블에는 클라이언트가 언제 마지막으로 접속했는지 관리하는 컬럼을 둔다.
이를 통해 클라이언트가 채팅방에 접속할 때마다 전체 N개의 메시지 레코드에 대해서 1 감소하는 UPDATE 쿼리를 실행하는 방법이다. 이를 ERD로 둔다면 다음과 같다.
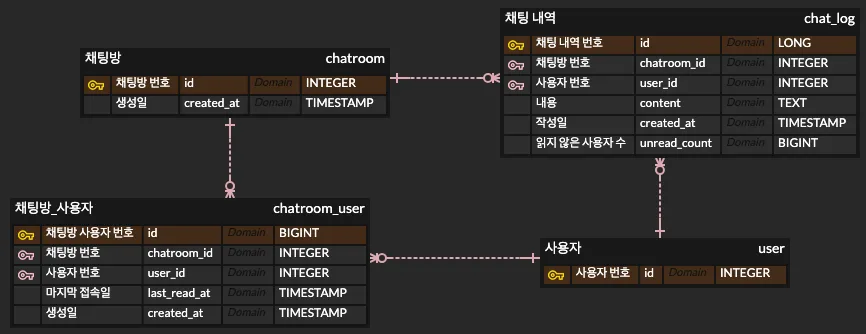
실제로 이 ERD로 구현할 것은 아니기 때문에 대충 설명하자면 마지막 접속일에 대한 컬럼을 두고, 클라이언트가 채팅방에 접속한다면 이를 최신으로 업데이트한다. 이전에 접속했던 마지막 접속일까지 채팅 내역의 작성일 기준으로 읽지 않은 클라이언트 수를 -1 하는 것이다.
하지만 이 방식은 장기간 미접속 클라이언트가 접속했을 경우 UPDATE 쿼리에 대해서 부담이 존재하지 않을까 생각하였고, 여러 클라이언트가 동시에 접속하게 되면 동시성 이슈도 발생하지 않을까 우려되는 부분이 있다.
커서와 온라인 상태를 활용한 방법
어떻게 해야 할까 생각하던 차에 개발자 커뮤니티인 오키에서 다음과 같은 댓글을 읽었다.
클라이언트가 마지막 읽은 메세지 순번을 기억시키는 방식이 가장 효율적입니다.
이 아이디어를 기반으로 최대한 간단하게 다음과 같이 ERD를 구성하였다.
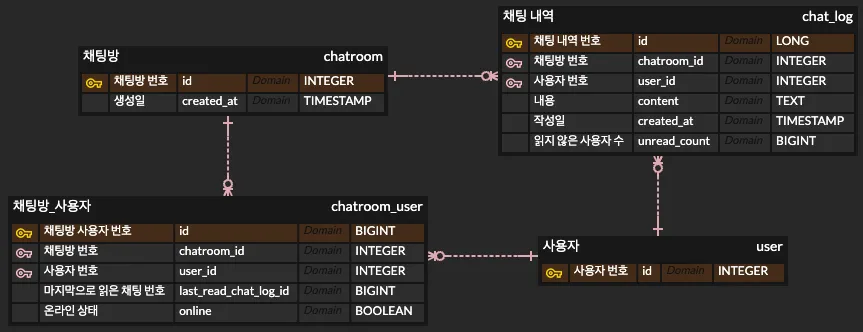
두 번째로 생각한 방법으로, 마지막으로 읽은 채팅 번호를 커서로 두고, 온라인 상태로 현재 클라이언트가 온라인 상태인지 판별하여 다음 쿼리를 통해 몇 명의 클라이언트가 메시지를 읽지 않았는지 판단하는 방법을 생각했다.
SELECT
cl.*,
(
SELECT COUNT(*)
FROM chatroom_user cu
WHERE cu.chatroom_id = cl.chatroom_id
AND cu.user_id <> cl.user_id
AND cu.last_read_chat_log_id < cl.id
) AS unread_count
FROM chat_log cl
WHERE cl.chatroom_id = :chatroomId
AND (:cursor IS NULL OR cl.id < :cursor)
AND NOT cu.online
ORDER BY cl.id DESC
LIMIT 20;
채팅 내역 테이블을 조인하여 마지막으로 읽은 채팅 번호와 현재 온라인 상태 여부에 따라서 각 채팅 레코드에 아직 읽지 않은 클라이언트 수를 집계하는 것이다. 이 방법은 한 가지 석연찮은 점이 있었는데, 바로 서버나 데이터베이스에 문제가 생겨서 특정 클라이언트의 온라인 상태가 오프라인 상태로 변하지 않는다면 읽음 처리를 할 때 클라이언트가 계속 읽고 있다고 판단될 수 있다고 생각하였다.
커서를 활용한 방법
따라서 최종적으로 온라인 상태를 판단하는 컬럼을 제거하고 다음과 같이 ERD를 구상하였다.
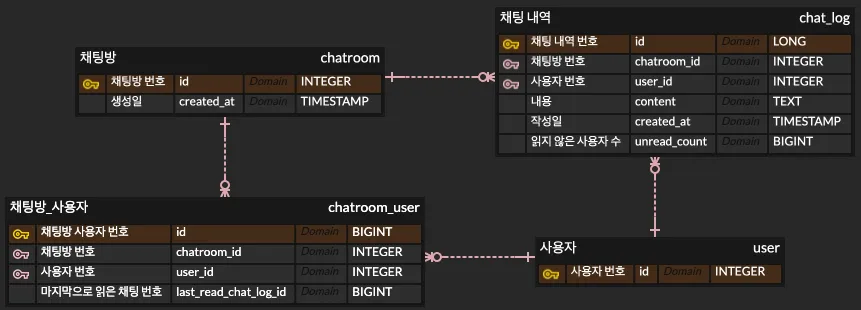
이때 클라이언트가 어디까지 메시지를 읽었는지 최신화 하는 방법에 대해서 초기에는 채팅 메시지가 서버에 전송될 때 마다 현재 접속중인 클라이언트가 최신 메시지까지 읽었다고 강제하는 방법이다. 하지만 이 방식은 매번 UPDATE 쿼리를 통해 데이터베이스를 갱신해야 하므로 연산 부담이 증가할 것 같았다.
따라서 클라이언트에게 몇 번 채팅까지 읽었다는 메시지를 전송받아서 데이터베이스에 최신화를 하고, 채팅방 토픽에 몇 번 클라이언트가 몇 번 채팅 ID까지 읽었다는 메시지를 브로드 캐스트 하여 클라이언트에서 읽지 않은 클라이언트와 데이터베이스의 읽지 않은 클라이언트의 데이터 정합성을 맞추는 방법을 생각하였다.
DDL
설명이 길었는데 DDL과 더미 데이터 INSERT까지 한 쿼리는 다음과 같다. 앞서 사용한 테이블을 삭제하기 위해서 DROP 문을 추가한 것을 확인할 수 있다.
DROP TABLE IF EXISTS chat_log CASCADE;
DROP TABLE IF EXISTS chatroom_user CASCADE;
DROP TABLE IF EXISTS chatroom CASCADE;
DROP TABLE IF EXISTS "user" CASCADE;
CREATE TABLE "user" (
id BIGSERIAL PRIMARY KEY
);
CREATE TABLE chatroom (
id BIGSERIAL PRIMARY KEY
);
CREATE TABLE chat_log (
id BIGSERIAL PRIMARY KEY,
chatroom_id BIGINT,
user_id BIGINT,
message TEXT,
created_at TIMESTAMPTZ DEFAULT now()
);
CREATE TABLE chatroom_user (
id BIGSERIAL PRIMARY KEY,
chatroom_id BIGINT,
user_id BIGINT,
last_read_chat_log_id BIGINT DEFAULT 0,
CONSTRAINT uk_chatroom_user_pair UNIQUE (chatroom_id, user_id)
);
INSERT INTO "user"(id) VALUES (1);
INSERT INTO "user"(id) VALUES (2);
INSERT INTO "user"(id) VALUES (3);
INSERT INTO chatroom(id) VALUES (1);
INSERT INTO chatroom_user(id, chatroom_id, user_id) VALUES (1, 1, 1);
INSERT INTO chatroom_user(id, chatroom_id, user_id) VALUES (2, 1, 2);
INSERT INTO chatroom_user(id, chatroom_id, user_id) VALUES (3, 1, 3);
INSERT INTO chat_log (chatroom_id, user_id, message, created_at)
SELECT
1,
(1 + (random() * 2)::int),
substring(md5(random()::text) from 1 for (1 + (random() * 10)::int)),
now() + (g * interval '1 second')
FROM generate_series(1, 20) g;
접속 이벤트에 따른 읽음 처리
클라이언트가 채팅방에 접속하는 것과 채팅방에 접속을 종료하는 것은 각각 해당 토픽에 구독한다와 구독한 토픽을 구독 해제한다는 경우의 수로 나눌 수 있다. 그리고 스프링에서는 이를 이벤트로 간주하며, 각 이벤트에 대한 처리를 할 수 있도록 @EventListener 어노테이션을 제공한다.
@EventListener
STOMP에서 발생하는 다양한 이벤트에 대해서 처리를 할 수 있는 어노테이션이다. 사용 방법은 다음과 같다.
@Component
public class StompEventListener {
@EventListener
public void listener(AbstractSubProtocolEvent event) {...}
}
여기서 AbstractSubProtocolEvent 를 상속한 이벤트 객체와 해당 객체가 사용되는 상황을 표를 통해 살펴보도록 하자.
| 이벤트 | 설명 |
|---|---|
| BrokerAvailabilityEvent | STOMP 브로커(내장/외부)의 사용 가능 여부가 변경될 때 발행. true면 브로커 사용 가능, false면 메시지 송수신 불가 상태. |
| SessionConnectEvent | 클라이언트가 STOMP CONNECT 프레임을 전송했을 때 발생. 아직 인증·연결 완료 전 단계. |
| SessionConnectedEvent | STOMP 브로커가 클라이언트의 CONNECT 요청을 승인하고 CONNECTED 프레임을 보낸 시점에 발생. 연결 확정. |
| SessionSubscribeEvent | 클라이언트가 특정 목적지(destination)에 SUBSCRIBE 요청을 보냈을 때 발생. |
| SessionUnsubscribeEvent | 클라이언트가 구독 해제(UNSUBSCRIBE) 요청을 보냈을 때 발생. |
| SessionDisconnectEvent | 클라이언트가 DISCONNECT 요청을 보내거나 세션이 종료될 때 발생. |
여기서 클라이언트가 채팅방에 접속한다는 것은 세션을 구독한다는 것이고, 접속을 종료한다는 것은 세션 구독을 해제 또는 연결이 끊겼다는 의미일 것이다. 따라서 SessionSubscribeEvent와 SessionUnsubscribeEvent 을 활용할 것이다.
여담으로 이를 활용하면 클라이언트에게 /user/queue/chat.info의 클라이언트 전용 경로를 먼저 구독하게 만들고, 각 채팅방에 접속할때마다 이벤트 리스너로 클라이언트에게 채팅 내역을 보내주는 등의 처리로 초반에 채팅방 접속 시 여러 요청을 보내는 것을 자동화 할 수도 있을 것이다.
기능 구현
그러면 이제 클라이언트가 채팅방을 접속했을 때와 채팅방을 나갈 때, 각 상황에 따라서 마지막으로 읽은 메시지와 온라인 여부를 업데이트 하도록 해보자.
레포지토리
레포지토리에 쿼리를 작성하기 전에 엔티티에 앞서 추가한 두 컬럼에 해당되는 필드를 먼저 추가해주자.
@Entity
@Table(name = "chatroom_user")
@Getter
public class ChatroomUser {
// ...
@Column(name = "last_read_chat_log_id")
private Long lastReadChatLogId;
}
JPA에는 업데이트 관련 쿼리가 없기 때문에 참고 자료를 활용하여 다음과 같이 업데이트 쿼리 메서드를 작성하였다.
@Repository
public interface ChatroomUserRepository extends JpaRepository<ChatroomUser, Long> {
// EntityManager.flush() && EntityManager.clear() 호출
@Modifying(clearAutomatically = true, flushAutomatically = true)
@Query(value = """
UPDATE chatroom_user cu
SET last_read_chat_log_id = (
SELECT COALESCE(MAX(cl.id), 0)
FROM chat_log cl
WHERE cl.chatroom_id = :chatroomId
)
WHERE cu.user_id = :userId
AND cu.chatroom_id = :chatroomId
""", nativeQuery = true)
void updateUserStatus(Long chatroomId, Long userId);
}
@Modifying(clearAutomatically = true, flushAutomatically = true)은 다음과 같은 처리를 수행한다.
- flushAutomatically: 이 쿼리 실행 전/후로 영속성 컨텍스트가 자동 flush되어 DB와 상태 불일치 최소화.
- clearAutomatically: 실행 후 1차 캐시를 비워 오래된 스냅샷으로 재노출되는 문제 방지.
채팅방 접속 상황은 클라이언트가 모든 채팅을 확인했다고 가정을 하고 현재 채팅방에 해당하는 가장 최신 채팅 ID로 갱신하도록 하였다.
이벤트 리스너
이벤트 리스너를 활용하여 작성한 메서드를 클라이언트 접속 및 접속 해제 상황마다 호출하도록 하자. 그 전에 기존에 사용하던 테스트 도구는 토픽 구독 및 구독 해제 상황에서 헤더를 보낼 수 있는 방법이 없다. 따라서 GPT에게 이걸 가능하게 해주는 HTML 파일을 만들어달라 했는데 생각보다 고퀄리티라서 참고자료에 코드를 공유한다.
@Component
@RequiredArgsConstructor
public class StompEventListener {
private final ChatroomUserRepository chatroomUserRepository;
@EventListener
@Transactional
public void listener(SessionSubscribeEvent event) {
SimpMessageHeaderAccessor accessor = getAccessor(event.getMessage());
Long userId = Long.parseLong(
Objects.requireNonNull(accessor.getFirstNativeHeader("userId"))
);
Long chatroomId = getChatroomId(accessor);
if (chatroomId == null) {
return;
}
chatroomUserRepository.updateUserStatus(chatroomId, userId);
}
@EventListener
@Transactional
public void listener(SessionUnsubscribeEvent event) {
SimpMessageHeaderAccessor accessor = getAccessor(event.getMessage());
Long userId = Long.parseLong(
Objects.requireNonNull(accessor.getFirstNativeHeader("userId")));
Long chatroomId = Long.parseLong(
Objects.requireNonNull(accessor.getFirstNativeHeader("chatroomId")));
chatroomUserRepository.updateUserStatus(chatroomId, userId);
}
private Long getChatroomId(SimpMessageHeaderAccessor accessor) {
String destination = accessor.getDestination();
if (destination == null || !destination.contains("/topic/chat")) {
return null;
}
String chatroomId = destination.substring(destination.lastIndexOf('.') + 1);
try {
return Long.parseLong(chatroomId);
} catch (NumberFormatException e) {
return null;
}
}
private SimpMessageHeaderAccessor getAccessor(Message<?> message) {
return SimpMessageHeaderAccessor.wrap(message);
}
}
사실 가장 간단하게 헤더로 처리했지만, 실제 채팅 서비스를 만든다면 세션 정보를 통해서 처리를 해야 할 것 같다고 생각한다. 클라이언트가 채팅을 하다가 갑자기 연결을 종료한다고 하면 SessionDisconnectedEvent가 발생하는데, 이를 로깅을 통해 확인해보면 다음과 같은 값들만 존재하기 때문이다.
@EventListener
@Transactional
public void listener(SessionDisconnectEvent event) {
SimpMessageHeaderAccessor accessor = getAccessor(event.getMessage());
log.info("{}", event);
log.info("{}", accessor);
}
SessionDisconnectEvent[sessionId=854cf080-bad6-3da7-d0e3-835f061458f7,
CloseStatus[code=1000, reason=null]]
SimpMessageHeaderAccessor [headers={simpMessageType=DISCONNECT,
stompCommand=DISCONNECT, simpSessionAttributes={},
simpSessionId=854cf080-bad6-3da7-d0e3-835f061458f7}]
지금은 읽음 기능 구현에만 초점을 맞추기 위해 구독을 할 때에는 헤더에 클라이언트 ID값을, 구독을 해제할 때는 헤더에 채팅방 ID와 클라이언트 ID를 보내서 클라이언트가 마지막으로 읽은 채팅 ID를 최신으로 갱신하도록 하겠다.
채팅 내역 읽음 처리 계산
메시지를 읽지 않은 클라이언트를 계산해야 한다. 우선 1번 채팅방을 대상으로 채팅 메시지 및 읽지 않은 클라이언트 수 계산을 위한 쿼리는 다음과 같다.
SELECT
cl.id,
cl.user_id,
cl.message,
cl.created_at,
(
SELECT COUNT(*)
FROM chatroom_user cu
WHERE cu.chatroom_id = cl.chatroom_id
AND cu.user_id <> cl.user_id
AND cu.last_read_chat_log_id < cl.id
) AS unread_count
FROM chat_log cl
WHERE cl.chatroom_id = :chatroomId
AND (:cursor IS NULL OR cl.id < :cursor)
ORDER BY cl.id DESC
LIMIT 20;
차근차근 보자면 채팅방과 클라이언트 가입 정보와 채팅 내역을 내부 조인하고, 그 레코드 중에서 다음 조건을 모두 충족하는 레코드를 조회한다.
- 가입 정보 테이블에 존재하는 마지막으로 읽은 채팅 ID보다 채팅 ID가 큰 레코드
- 채팅 내역 중에서 각 클라이언트가 작성한 레코드는 제외
이후 GROUP BY를 통해 채팅 내역을 하나로 묶은 다음에 조회된 chatroom_user 레코드를 COUNT() 연산 처리하면 된다고 생각했다. 그리고 이 쿼리를 AI에게 최적화를 맡겨봤더니 다음과 같이 쿼리를 작성해줬다.
WITH page AS (
SELECT id, user_id, message, created_at, chatroom_id
FROM chat_log
WHERE chatroom_id = :chatroomId
AND (:cursor IS NULL OR id < :cursor)
ORDER BY id DESC
LIMIT 20
),
members AS (
SELECT user_id, last_read_chat_log_id
FROM chatroom_user
WHERE chatroom_id = :chatroomId
)
SELECT
p.id,
p.user_id,
p.message,
p.created_at,
(
SELECT COUNT(*)
FROM members m
WHERE m.user_id <> p.user_id
AND m.last_read_chat_log_id < p.id
) AS unread_count
FROM page p
ORDER BY p.id DESC
내 자리는 어디에…
구현
레포지토리
레포지토리에서는 조금 색다르게 Native Query와 Interface Projection을 활용하여 처리하였다.
public interface ChatMessage {
Long getId();
Long getUserId();
String getMessage();
Long getUnreadCount();
LocalDateTime getCreatedAt();
}
이 반환 타입을 활용하여 다음과 같이 네이티브 쿼리를 작성하였다.
@Repository
public interface ChatLogRepository extends JpaRepository<ChatLog, Long> {
@Query(value = """
WITH page AS (
SELECT id, user_id, message, created_at, chatroom_id
FROM chat_log
WHERE chatroom_id = :chatroomId
AND (:cursor IS NULL OR id < :cursor)
ORDER BY id DESC
LIMIT 20
),
members AS (
SELECT user_id, last_read_chat_log_id
FROM chatroom_user
WHERE chatroom_id = :chatroomId
)
SELECT
p.id,
p.user_id,
p.message,
p.created_at,
(
SELECT COUNT(*)
FROM members m
WHERE m.user_id <> p.user_id
AND m.last_read_chat_log_id < p.id
) AS unread_count
FROM page p
ORDER BY p.id DESC
""", nativeQuery = true)
List<ChatMessage> findByChatroomIdWithUnreadCountWithCursor(Long chatroomId, Long cursor);
}
서비스
서비스는 다음과 같이 수정하였다. 이전 포스팅에서는 커서의 존재 여부에 따라서 다른 메서드를 호출했지만 메서드를 하나로 통합했으므로 커서의 유무와 관계 없이 다음과 같이 간단하게 호출이 가능하다.
@Slf4j
@Service
@Transactional
@RequiredArgsConstructor
public class ChatService {
private final ChatLogRepository chatLogRepository;
// ...
@Transactional(readOnly = true)
public List<MessageResponse> findChatLog(Long chatroomId, Long cursor) {
return chatLogRepository.findByChatroomIdWithUnreadCountWithCursor(chatroomId, cursor)
.stream().map(chatMessage ->
MessageResponse.of(
chatMessage.getId(),
chatMessage.getUserId(),
chatMessage.getMessage(),
chatMessage.getUnreadCount(),
chatMessage.getCreatedAt()
)).toList();
}
}
테스트
테스트를 위해서 다음과 같은 쿼리를 통해 클라이언트 정보를 수정할 것이다.
UPDATE chatroom_user SET last_read_chat_log_id = 10 WHERE user_id = 1;
UPDATE chatroom_user SET last_read_chat_log_id = 15 WHERE user_id = 3;
UPDATE chatroom_user SET last_read_chat_log_id = 10 WHERE user_id = 2;
UPDATE chat_log SET user_id = 2 WHERE id > 10;
상황은 다음과 같다. 1번 클라이언트는 10번 채팅까지 채팅을 읽은 다음에 채팅방을 떠났고, 3번 클라이언트는 10번 채팅부터 15번 채팅까지 채팅방에 접속했다가 떠난 상태라고 가정해보자. 이때 2번 클라이언트는 10번 채팅부터 채팅방에 접속하여 추가로 채팅 메시지 10개를 전송하여 총 20개의 채팅 메시지가 존재한다.
이 상황에서 2번 클라이언트로 채팅 로그를 확인해보면 다음과 같다.
메시지 from /user/queue/chat.log
headers:
content-length: 1769
message-id: 158b2972-9510-746d-fbaa-1d04d880119b-1
subscription: sub-1
content-type: application/json
destination: /user/queue/chat.log
[
{
"message": "1ba",
"id": 20,
"unreadCount": 2,
"userId": 2,
"createdAt": "2025-08-23T12:21:37.51937"
},
// ...
{
"message": "a9d6",
"id": 16,
"unreadCount": 2,
"userId": 2,
"createdAt": "2025-08-23T12:21:33.51937"
},
{
"message": "2485d90a",
"id": 15,
"unreadCount": 1,
"userId": 2,
"createdAt": "2025-08-23T12:21:32.51937"
},
// ...
{
"message": "d2a6a13a27",
"id": 11,
"unreadCount": 1,
"userId": 2,
"createdAt": "2025-08-23T12:21:28.51937"
},
{
"message": "46257f1",
"id": 10,
"unreadCount": 0,
"userId": 3,
"createdAt": "2025-08-23T12:21:27.51937"
},
// ...
{
"message": "19079d0d",
"id": 1,
"unreadCount": 0,
"userId": 3,
"createdAt": "2025-08-23T12:21:18.51937"
}
]
중간에 주석 부분은 unreadCount가 같다는 의미로 보면 된다. 자세히 보면 10번 채팅까지는 모든 클라이언트가 읽었고, 11번 부터 15번 채팅 까지는 2번과 3번 클라이언트가 읽었다. 이후 16번 부터 20번 채팅 까지는 2번 클라이언트를 제외한 다른 클라이언트는 채팅방에 존재하지 않기 때문에 읽지 않은 클라이언트는 1번 클라이언트와 3번 클라이언트 2명이 된다.
읽은 메시지 최신화
현재 구조에서는 실시간 접속중인 클라이언트들도 주기적으로 최신화 요청을 보내어 읽은 메시지를 최신화 해야 한다. 이를 위해서 클라이언트에게 가장 최신으로 읽은 메시지 ID를 요청값으로 받는다고 가정하고 간단하게 구현해보았다.
구현
레포지토리
@Repository
public interface ChatroomUserRepository extends JpaRepository<ChatroomUser, Long> {
// ...
Optional<ChatroomUser> findByChatroomIdAndUserId(Long chatroomId, Long userId);
}
JPA의 Dirty Checking 기능을 활용하여 UPDATE 처리를 하도록 하겠다.
서비스
서비스에서는 컨트롤러에 클라이언트 ID와 해당 클라이언트가 이전에 읽은 최신 채팅 ID와 현재 읽은 최신 채팅 ID를 담아서 반환할 것이다.
@Service
@Transactional
@RequiredArgsConstructor
public class ChatService {
private final ChatLogRepository chatLogRepository;
private final ChatroomUserRepository chatroomUserRepository;
// ...
public UserReadInfoResponse changeUserReadInfo(Long chatroomId, Long userId, Long currentReadId) {
ChatroomUser chatroomUser = chatroomUserRepository.findByChatroomIdAndUserId(chatroomId, userId).orElseThrow();
Long prev = chatroomUser.getLastReadChatLogId();
chatroomUser.changeLastReadChatLogId(currentReadId);
return UserReadInfoResponse.of(userId, prev, currentReadId);
}
}
구현을 위해 엔티티와 반환 객체를 다음과 같이 작성하였다.
public record UserReadInfoResponse(
Long userId,
Long fromInclusive,
Long toInclusive
) {
public static UserReadInfoResponse of(Long userId, Long prev, Long cur) {
return new UserReadInfoResponse(userId, prev + 1, cur);
}
}
@Entity
@Table(name = "chatroom_user")
@Getter
public class ChatroomUser {
// ...
public void changeLastReadChatLogId(Long lastReadChatLogId) {
this.lastReadChatLogId = lastReadChatLogId;
}
}
컨트롤러
컨트롤러는 다음과 같이 작성하였다.
@Slf4j
@Controller
@RequiredArgsConstructor
public class StompController {
private final ChatService chatService;
private final SimpMessagingTemplate messagingTemplate;
// ...
@MessageMapping("/chat.change.message.{chatroom-id}")
public void changeLastReadMessageId(
@DestinationVariable("chatroom-id") Long chatroomId,
@Header(name = "simpSessionId") String simpSessionId,
@Header(name = "userId") Long userId,
@Header(name = "currentReadId") Long currentReadId
) {
UserReadInfoResponse response = chatService.changeUserReadInfo(chatroomId, userId, currentReadId);
messagingTemplate.convertAndSendToUser(
simpSessionId,
"/queue/chat.info",
response,
createHeaders(simpSessionId)
);
}
private MessageHeaders createHeaders(@Nullable String sessionId) {
SimpMessageHeaderAccessor headerAccessor = SimpMessageHeaderAccessor
.create(SimpMessageType.MESSAGE);
if (sessionId != null) {
headerAccessor.setSessionId(sessionId);
}
headerAccessor.setLeaveMutable(true);
return headerAccessor.getMessageHeaders();
}
}
테스트
이제 1번 채팅방에 1번 클라이언트가 15번 채팅까지 읽음 처리를 했다고 가정하고 요청을 보내보자.
>>> SUBSCRIBE
userId:1
ack:auto
id:sub-1
destination:/user/queue/chat.info
>>> SEND
destination:/app/chat.change.message.1
userId:1
currentReadId:15
Received data
<<< MESSAGE
content-length:51
message-id:3375ff31-89f7-da26-af07-c6ee28133eba-0
subscription:sub-1
content-type:application/json
destination:/user/queue/chat.info
content-length:51
headers:
content-length: 51
message-id: 3375ff31-89f7-da26-af07-c6ee28133eba-0
subscription: sub-1
content-type: application/json
destination: /user/queue/chat.info
{"userId":1,"fromInclusive":11,"toInclusive":15}
실시간 채팅 읽음 처리
이렇게 카톡 처럼 채팅 내역을 조회했을 때 채팅방에 접속중인 클라이언트와 자신을 제외하고 몇 명의 클라이언트가 읽지 않았는지 보여주는 기능을 구현하였다. 그러면 실시간 채팅은 어떻게 안읽음 처리를 구현해야 할까?
이미 앞서서 클라이언트가 어디까지 메시지를 읽었는지 처리할 수 있었다. 따라서 이 부분은 단순하게 실시간 채팅을 보낼 때 전체 사용자 수 - 1을 하여 우선 보내놓고, 시간이 지나 각 클라이언트가 읽은 메시지 갱신 요청에 따라서 UI를 갱신하면 된다.
구현
레포지토리
좀 더 최적화할 수 있겠지만, 간단하게 클라이언트가 채팅을 전송할때마다 chatroom_user 테이블에 COUNT 쿼리를 통해 해당하는 채팅방의 전체 클라이언트 수를 구하도록 하자.
@Repository
public interface ChatroomUserRepository extends JpaRepository<ChatroomUser, Long> {
// ...
Long countByChatroomId(Long chatroomId);
}
서비스
이제 채팅을 저장하고, 내부적으로 읽지 않은 클라이언트 수를 구한 다음에 반환하도록 서비스 메서드를 수정해보도록 하자.
@Slf4j
@Service
@Transactional
@RequiredArgsConstructor
public class ChatService {
private final ChatLogRepository chatLogRepository;
private final ChatroomUserRepository chatroomUserRepository;
public MessageResponse saveMessage(MessageSendingDto dto) {
ChatLog savedChatLog = saveChatLog(dto);
Long unreadCount = chatroomUserRepository.countByChatroomId(savedChatLog.getChatroomId());
return MessageResponse.of(
savedChatLog.getId(),
savedChatLog.getUserId(),
savedChatLog.getMessage(),
unreadCount - 1,
savedChatLog.getCreatedAt()
);
}
// ...
}
테스트
1번 채팅방에 2번 클라이언트로 접속한 다음에 테스트를 진행해보았다.
headers:
content-length: 88
message-id: c76ab00b-daab-a58e-c082-6063cf96cc05-0
subscription: sub-0
content-type: application/json
destination: /topic/chat.1
{"id":21,"userId":2,"message":"HEELO","unreadCount":2,"createdAt":"2025-08-22T20:55:23.957368"}
성공적으로 읽지 않은 클라이언트 데이터가 전달된 것을 확인할 수 있다.
이 기능을 어떻게 구현할 지 막막해서 이번 주 블로그는 다른 주제로 해야하나 싶었는데 다행히 나름 잘 구현된 것 같아서 뿌듯하다. 물론 다중 디바이스 상황이라던가 캐싱을 활용한 최적화 같은 개선안이 더 있을 것 같지만, 더 하다가는 머리가 아파서… 아무튼 다음 포스팅은 채팅 서버를 스케일 아웃 하기 위해서 어떤 처리를 해야 하는 지에 대해 다뤄볼 것이다.
참고 자료
WebSocket, STOMP in springboot
Spring-data-JPA [4] Update와 @Query
댓글남기기